语音交互产品的认知
因为用户是结果导向的,无论我们怎么吹嘘自己的产品有多智能,响应速度有多快,理解能力有多强,什么网络神经中枢、神经网络引擎,只要用户在使用过程中没感觉到它的智能点,一切貌似都白搭。

在目前的AI产品体系中,广为人知的主要是三大方向,分别是:图像(即人脸识别)、智能推荐(类似于各种推荐引擎产品,如今日头条等)以及语音交互。
图像很好理解,去年很火的Face ID就是基于此而设计,早期的话像是很多公司会采用的“面部识别打卡”、脸部识别登录设备等也都是相关的应用。而智能推荐则是通过分析用户的日常行为、操作等获得用户画像,从而分析出用户的喜好,为用户生成并推荐其感兴趣的内容。说“抖音”一刷就停不下来,很重要的一个原因就是因为它推荐的内容多半都是用户感兴趣的内容,这就依赖于其智能的算法。
那至于“语音交互”,它究竟是什么?
语音交互是基于语音输入的新一代交互模式,通过说话就可以得到反馈结果。生活中最常见的就是手机内置的各种“语音助手”:魅族的小溪、IPhone的siri以及小米的小爱等,都是相关的产品或者功能。

一.“语音交互”的定义
“语音交互”可以这么来理解:人类与设备通过自然语言完成了信息的传递。
在这里我们把它分成了简单的四个内容:
1. 人类与设备
语音交互,属于“人机交互”的一种,是人类与机器之间的沟通、联系,比如和手机,和电脑,甚至“智能家居”概念中的和电器。“语音交互”的对象是人与设备,而非人与人,如微信,其实就是用户通过微信与另一个用户形成沟通,这自然就不属于“人类与设备”的范畴。
2. 自然语言
是指一种自然地随文化演化的语言,如汉语、英语、法语等,但如为计算机而设置的语言,即为“人造语言”。自然语言是人类交流和思维的主要工具,对于自然语言的处理也是人工智能中最为困难的问题之一。
“语音交互”是需要人发出声音从而与设备产生互动,比如设闹钟,我们喊“Siri,给我设置一个明天早上八点的闹钟”,这就是通过自然语言与设备完成了一次互动,而不是传统的“打开闹钟-设置时间”这样的手动操作。因此很重要的一点就是“自然语言”,我们通过设备定了闹钟,然后它发出了声音,看起来我们是和设备完成了一次互动,但它发出的不是自然语言,而是铃声,即使你是用“人声”来充当闹铃,那也不是我们在“语音交互”中所定义的“自然语言”。
3. 信息的传递
即我们通过自然语言与设备完成了某次互动,比如定闹钟、查导航等,这之间一定是发生了某次信息从我们这边流转到了设备,之后再又回到我们这边,一个双向传递的过程。只是有时候设备给的回应也许是语言,也许是执行任务。
二. 交互方式的发展
人与设备的交互方式大致经历了三个阶段的演变:PC时代、移动时代以及AI时代。

在PC时代,我们主要靠鼠标、键盘的外接设备进行输入,比如鼠标双击某个图标打开对应的软件,要打字也需要敲击键盘才能一个一个字符的实现,这样子的模式很笨重,不灵便。
之后过渡到了移动时代,现在几乎人手一台手机,想要点开什么app,主要手指轻轻一点即可开启,此时我们进行交互的方式变成了触摸。所以为什么手机发展到如今,十余年的时间过去了,依旧停留在“触摸”上,那是因为与传统的外接设备来实现输入相比,它本身已经做到了跨越,而其下一个阶段又还在伊始阶段,因此也无法完全被取代。
等什么时候“手机”变成“嘴机”了,也许就发生变革了。
下一个时代也就是“AI时代”,也就是我们所在讨论的“语音交互”时代。科幻电影大家看得不少,很多科幻电影之所以精彩就是因为它展现了未来科技可能的面貌。比如“钢铁侠”中,Tony与其研制的人工智能“J.A.R.V.I.S”就存在着及其精彩的交互。(感兴趣的自行搜索视频呦~)
但目前“语音交互”时代,其实还是主要停留在“语音输入”这一内容上,即我们对设备发出一个指令:给我定闹钟、告诉我怎么去等等,然后设备通过执行再输出相应的内容,这个是死板的,或者说是程序化的。设备只会给你定你所选择的时间点的闹钟,它也只会告诉你怎么去,诚然,这是我们想要的,但不够人性化。
当真正地实现“交互”时,我们所期待的场景应该是:我说我要去XX地,设备读取指令,经过分析之后反馈:那个地方不远,平时走路过去就行,但现在外面下着大雨,我可以为你叫一辆出租车,估计8分钟左右就能到达。
顺着这个思路,我们再聊聊“语音交互”的一个发展历史。
三. “语音交互”的发展历史
主要也是三个阶段:单向收听、单向输入、双向交流。

1. 单向收听
人人都经历过,如10086的电子助手。我们在拨打10086时,给我们回应的肯定不是人工客服,而是电子语音:“查询话费请按1,套餐及流量办理请按2”。只有在电子语音无法解决用户的需求时,才会在最后说:“如需人工帮助请按0”。
这种是被动的,用户只能被动地接受已经预先设置好的服务,它无法更改,更无法对用户在电话那头的话语做出任何回应,唯一能够令它产生变化的就是用户按动相应的数字键。
2. 单向输入
最常见的应用就是各种输入法的“语音识别转文字”,也就是通常所说的“语音输入法”。通过说话让应用识别,之后以文字的形式转出。很多时候可能一段长对话需要我们敲键盘敲好久,随着这一技术的成熟发展,我们直接说出这段话,之后往往只需要修改几个标点符合与错别字就能很快地完成一段文字的输入。
但其最大的缺点依然是无法形成互动,仍旧是单向的,只不过是从输出者变成了输入者。这种时候它更像是一种工具,当我们不想打字的时候才会用,毕竟当我们用设备进行语音转文字处理时,它不会自动反馈说:我觉得你这边说的不好,需要进行修改。
3. 双向交流
顾名思义,人与设备开始形成互动,即所谓的语音助手,它能帮你处理部分任务、设定某些事项,同时也能进行一些简单的聊天沟通。你输入的同时,也能得到来自设备的输出,从而形成一定的互动。
当然,它还远远不成熟,或者说,还没那么智能,就像一个孩子,ta也会对你哭对你笑,但当你讲一些它听不明白的话时,ta也只会睁着眼睛看着你,因为它所涉及到的技术也相对最复杂。
举个例子:“单向收听”就像是听收音机,你在收音机前的喜怒哀乐电台主播并不知道,你只是在听;“单向输入”就像是在KTV唱歌,你唱完这首要么继续下一首要么机器显示没歌了,并不会有任何人性化的反馈(除去那些有评分功能的KTV系统);“双向交流”,就真的是接近人与人之间的沟通交流,就像是两个人在打电话,互相说着喜怒哀乐。
最后我们来讨论一下相关的实现原理,这也是“语音交互”技术中最核心的一部分。
四.“语音交互”的实现原理
在网上看了徐嘉南老师的视频,获益匪浅,他目前是百度的高级产品经理,他将“语音交互”的实现原理简单地概括为一个过程,即:用户说话,系统识别并理解,之后再转换成声音反馈出来。
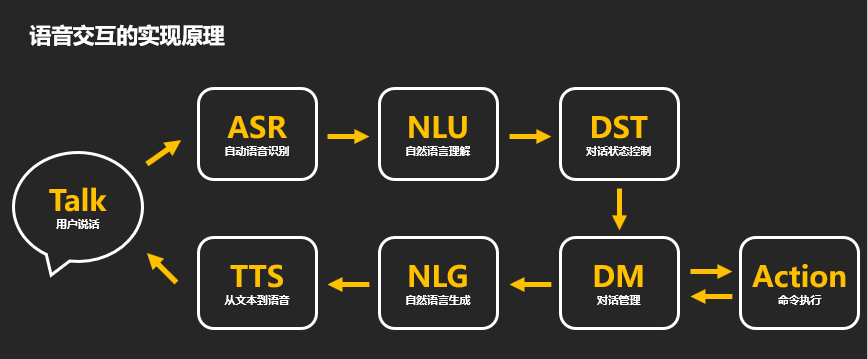
接下来我对相关的过程进行一个简单的概述。
Talk:用户发出声音——也就是前面所提及的“自然语言”,无论是哪国的,用户通过说话来与设备形成信息的传递。只有这样,才会有后续一系列的步骤产生。毕竟我们讨论的是“语音交互产品”,用户必须发声才能形成互动,而不是用户坐在沙发上设备就能说“你想要茶还是咖啡?”。
ASR(Automatic Speech Recognition):自动语音识别——在这个时候,机器通过听取用户发出的声音,将其转化为“文字”供机器读取,也就是俗称的“语音听写机”,是实现“声音”到“文字”转换的技术。在这一环节我们比较常见的就是各种“语音输入法”的功能了。
这一环节也是比较容易出错的环节,有时候用户说话有口音,或者说话比较快,设备就很容易转化出错误的文字。
NLU(Natural Language Understanding):自然语言理解——此时机器尝试理解文字,这也是目前在“语音交互产品”中较难突破的一点,也是核心的一点。很简单,交互如何实现完美,很重要的就是建立在“互相理解”的基础上。或者说一场对话如何得以成功进行,很重要的一点就是互相理解对方所说的话的含义。
比如用户说“我觉得今天天气不错,适合出去游玩”,潜台词就是“我想在这样美好的日子里出去转转,你能给我一点建议吗?”,但机器却错误理解成“他想在出去玩之前吃点饭”,于是推荐了各种外卖的联系方式。如此这样一次的“交互”就是失败的,因为机器没用理解用户的意思,也就是我们老话常说的“对牛弹琴”。
DST(Dialogue State Tracker):对话状态控制 & DM(Dialogue Manager):对话管理——这两个可以放在一起进行讨论。举例来说,比如用户说“给我订张机票”,很显然,这个对话所对应的信息是不完整的,因为没有时间,没有目的地与出发地。这个时候系统判断相应的指令存在信息缺失,或者说它作出判断,接下来是不是该我说话了,于是它就会问:“请问你想从哪里出发?要去哪里?什么时候出发?”。
因此在这两个阶段,机器主要进行的判断就是这个对话进行到哪一步了,该用户说话还是机器说话了。因为如果对话完整,机器就可以执行相应的命令,如果不完整,它就需要再问一次用户,以将内容补完。
Action:命令执行——很好理解,为什么它会单独分出一条并与DM形成双向,也就是我们前面所说的,如果这次命令是完整的,用户说的是“给我定明早8:00的闹钟”,那么系统只需依照指令设置好闹钟,再给出反馈“闹钟已设置好”,那么这么一次的互动就算完成了。但如果用户说的是“给我定闹钟”,显然设备无法执行相关命令,于是需要生成相应的对话来提示用户补充完整时间,之后再执行命令。
因此一定程度上也可以理解为Action,是独立于“语音交互”过程外的,只有在这么一次交互的信息是完整的时候,它才会执行命令。
NLG(Natural Language Generation):自然语言生成——这时候系统经过语义的理解+对话状态控制,对用户发出的自然语言已经进行了解析,知道自己该做出怎样的回应了,此时就会生成相对应的自然语言。比如用户选择的模式是汉语,那他说的是汉语,机器同样也应该以汉语的形式进行回答。这时候就是设备开始给出回应的时候了。
TTS(Text To Speech):从文本到语音——很简单来说,就是把“文字”转换成“声音”,算是ASR技术的逆推,只是在这一过程中,就很容易反映出其“人性化”的一面,需要设计师在其中添加多种丰富的话术,甚至于对音调、音色乃至断句等都有要求,不然就会显得“机械化”,不够“拟人化”。
比如用户说“我想吃外卖”,机器回答“好的,已为你找到附近的十家外卖店,其中沙县小吃离你最近”;还有一种回答是“好的,这边已经找到距离你最近的一家饭店,是沙县小吃,网上评价还不错,据说那边的馄饨面很不错,建议可以尝试”。很显然,最终推荐的都是那家沙县小吃,但是后者稍显人性。同样的,一模一样的句子,如果用不同的语调、音色来发出,给人的感觉同样不同。
五. 总结

在这一系列过程中,ASR主要发生在“识别前”,这里着重的就是对用户发出声音的“识别灵敏度”,因为要先听清楚,才有机会听懂。这里所需要攻克的点就是“声音信号的识别与优化”。
NLU发生在“识别中”,也是在整个语音交互过程中最难的一部分,因为需要机器去理解人类发出的语言,而机器没有感情,就像用户说“我去你大爷”,也许机器会理解成“用户要去他大爷家”,而不知道其实用户是在说脏话。这一环节着重于“机器对声音信号的理解”,机器人性化与否从这里开始产生改变。
TTS发生在“识别后”,也是用户能真正直观感受到的方面,因为在这一阶段设备才算是与用户形成互动。用户不理解什么机器语言,他们只想感受到机器能不能在听完我说的之后给我我想听到的回答。有时候即使机器没理解到位,但它反馈出的内容却能令用户耳目一新,同样能够凸显产品的价值。这一环节需要注意的点是“信息的反馈与播报”。
打个比喻,我们把读书时候的考试前的准备过程理解为是“ASR”,我们要去记知识点;考试过程为“NLU”,我们把记到的知识点实际应用到试卷的问题当中去;考试结果公布的过程即为“TTS”,只要结果是差的,无论前两个过程再努力也很难得到认可,反之只要最后反馈的结果是好的,哪怕之前的工作都不到位,貌似也能让人称赞一句。(当然,世上没有不劳而获的事,前期的准备才能在最后获得好的结果)
因为用户是结果导向的,无论我们怎么吹嘘自己的产品有多智能,响应速度有多快,理解能力有多强,什么网络神经中枢、神经网络引擎,只要用户在使用过程中没感觉到它的智能点,一切貌似都白搭。
因此在设计一款“语音交互产品”的过程中,每一环节都很重要。目前最大的语音交互平台是“亚马逊”,在其平台上有超过两万个语音交互类产品,而国内却不超过300个,连其零头都未触及。“语音交互产品”潜力巨大,尤其是近年来“物联网”的势头正足,5G网络宣告展开,我想未来的浪潮中一定会有“语音交互产品”的一席之地。

时间:2018-09-25 00:09 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















