从Spark MLlib到美图机器学习框架实践
MLlib 是 Apache Spark 的可扩展机器学习库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模的数据集。
/ 机器学习简介 /
在深入介绍 Spark MLlib 之前先了解机器学习,根据维基百科的介绍,机器学习有下面几种定义:
• 机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能;
• 机器学习是对能通过经验自动改进的计算机算法的研究;
• 机器学习是用数据或以往的经验,以此优化计算机程序的性能标准;
• 一种经常引用的英文定义是「A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.」。
*加粗的是重点/加粗的是重点/加粗的是重点
其实在「美图数据技术团队」之前的科普文章贝叶斯概率模型一览曾介绍过,机器学习狭义上是指代统计机器学习,统计学习根据任务类型可以分为监督学习、半监督学习、无监督学习、增强学习等。

机器学习常用的算法可以分为以下种类:
1.构造间隔理论分布:人工神经网络、决策树、感知器、支持向量机、集成学习AdaBoost、降维与度量学习、聚类、贝叶斯分类器;
2.构造条件概率:高斯过程回归、线性判别分析、最近邻居法、径向基函数核;
3.通过再生模型构造概率密度函数:最大期望算法、概率图模型(贝叶斯网和 Markov 随机场)、Generative Topographic Mapping;
4.近似推断技术:马尔可夫链、蒙特卡罗方法、变分法;
5.最优化算法。
/ Spark MLlib /
在上文我们曾提到机器学习的重点之一是「经验」,而对于计算机而言经验往往需要经过多轮迭代计算才能得到,而 Spark 擅长迭代计算,正好符合机器学习这一特性。在 Spark 官网上展示了逻辑回归算法在 Spark 和 Hadoop 上运行性能比较,从下图可以看出 MLlib 比 MapReduce 快了 100 倍。

Spark MLlib 主要包括以下几方面的内容:
• 学习算法:分类、回归、聚类和协同过滤;
• 特征处理:特征提取、变换、降维和选择;
• 管道(Pipeline):用于构建、评估和调整机器学习管道的工具;
• 持久性:保存和加载算法,模型和管道;
• 实用工具:线性代数,统计,最优化,调参等工具。

上表总结了 Spark MLlib 支持的功能结构,可以看出它所提供的算法丰富,但算法种类较少并且老旧,因此 Spark MLlib 在算法上支持与 kylin 项目有些脱节,它的主要功能更多是与特征相关的。
ML Pipelines
从 Spark 2.0 开始基于 RDD 的 API 进入维护模式,Spark 的主要机器学习 API 现在是基于 DataFrame 的 API spark.ml,借鉴 Scikit-Learn 的设计提供了 Pipeline 套件,以构建机器学习工作流。 ML Pipelines 提供了一套基于 DataFrame 构建的统一的高级 API ,可帮助用户创建和调整实用的机器学习流程。
*「Spark ML」不是官方名称,偶尔用于指代基于 MLlib DataFrame 的 API
首先了解 ML Pipelines 内几个重要组件。
DataFrame
DataFrame 让 Spark 具备了处理大规模结构化数据的能力。

RDD 是分布式 Java 对象的集合,对象的内部数据结构对于 RDD 而言不可知。DataFrame 是一种以 RDD 为基础的分布式数据集,RDD 中存储了 Row 对象,Row 对象提供了详细的结构信息,即模式(schema),使得 DataFrame 具备了结构化数据的能力。
Transforme
Transformer 通常是一个数据/特征变换的类,或一个训练好的模型。
每个 Transformer 都有 transform 函数,用于将一个 DataFrame 转换为另一个 DataFrame 。一般 transform 的过程是在输入的 DataFrame 上添加一列或者多列 ,Transformer.transform也是惰性执行,只会生成新的 DataFrame 变量,而不会去提交 job 计算 DataFrame 中的内容。

Estimator
Estimator 抽象了从输入数据学习模型的过程,每个 Estimator 都实现了 fit 方法,用于给定 DataFrame 和 Params 后,生成一个 Transformer(即训练好的模型),每当调用 Estimator.fit() 后,都会产生 job 去训练模型,得到模型参数。
Param
可以通过设置 Transformer 或 Estimator 实例的参数来设置模型参数,也可以通过传入 ParamMap 对象来设置模型参数。

Pipeline
Pipeline 定义了一组数据处理流程,可以在 Pipeline 中加入 Transformer、Estimator 或另一个 Pipeline。Pipeline 继承自 Estimator,调用 Pipeline.fit 方法后返回一个 Transformer——PipelineModel;PipelineModel 继承自 Transformer,用于将输入经过 Pipeline 的各个 Transformer 的变换后,得到最终输出。
Spark MLlib 典型流程如下:
• 构造训练数据集
• 构建各个 Stage
• Stage 组成 Pipeline
• 启动模型训练
• 评估模型效果
• 计算预测结果
通过一个 Pipeline 的文本分类示例来加深理解:
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// Prepare training documents from a list of (id, text, label) tuples.
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
// Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
// Fit the pipeline to training documents.
val model = pipeline.fit(training)
// Now we can optionally save the fitted pipeline to disk
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
// We can also save this unfit pipeline to disk
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
// And load it back in during production
val sameModel = PipelineModel.load("/tmp/spark-logistic-regression-model")
// Prepare test documents, which are unlabeled (id, text) tuples.
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// Make predictions on test documents.
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}
模型选择与调参
Spark MLlib 提供了 CrossValidator 和 TrainValidationSplit 两个模型选择和调参工具。模型选择与调参的三个基本组件分别是 Estimator、ParamGrid 和 Evaluator,其中 Estimator 包括算法或者 Pipeline;ParamGrid 即 ParamMap 集合,提供参数搜索空间;Evaluator 即评价指标。
CrossValidator

via https://github.com/JerryLead/blogs/blob/master/BigDataSystems/Spark/ML/Introduction%20to%20MLlib%20Pipeline.md
CrossValidator 将数据集按照交叉验证数切分成 n 份,每次用 n-1 份作为训练集,剩余的作为测试集,训练并评估模型,重复 n 次,得到 n 个评估结果,求 n 次的平均值作为这次交叉验证的结果。接着对每个候选 ParamMap 重复上面的过程,选择最优的 ParamMap 并重新训练模型,得到最优参数的模型输出。
举个例子:

TrainValidationSplit
TrainValidationSplit 使用 trainRatio 参数将训练集按照比例切分成训练和验证集,其中 trainRatio 比例的样本用于训练,剩余样本用于验证。
与 CrossValidator 不同的是,TrainValidationSplit 只有一次验证过程,可以简单看成是 CrossValidator 的 n 为 2 时的特殊版本。
举个例子:

实现自定义 Transformer
继承自 Transformer 类,实现 transform 方法,通常是在输入的 DataFrame 上添加一列或多列。
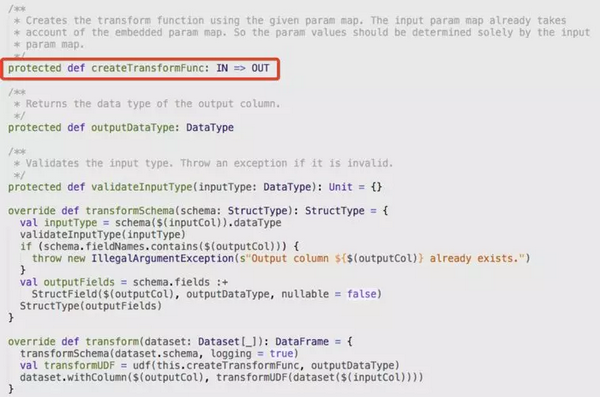
对于单输入列,单输出列的 Transformer 可以继承自 UnaryTransformer 类,并实现其中的 createTransformFunc 方法,实现对输入列每一行的处理,并返回相应的输出。

/ 自研机器学习框架 /
机器学习技术日新月异,却缺少高效灵活的框架降低新技术的调研成本,而经验与技术往往需要通过框架和工具来沉淀,并且算法人员常常受限于算力,导致离线证明有效的模型,因为预估时间复杂度过高而无法上线。

据此美图数据技术团队以「开发简单灵活的机器学习工作流,降低算法人员的新算法调研成本及工程人员的维护成本,并且提供常用的领域内解决方案,将经验沉淀」的目标搭建了一套量身定制的机器学习框架用以解决上述问题,尤其是解决在推荐算法相关任务上遇到的问题。该框架总共包括 3 个组件:Spark Feature、Bamboo 与 Online Scorer。
Spark Feature:训练样本生产

该组件主要用于训练样本的生产,实现了灵活高效的样本特征编码,可以实现将任意特征集合放在同一个空间进行编码,不同特征集合共享编码空间;为此我们提出了两个概念:第一个是「域」,用于定义共享相同建模过程的一组特征;第二个是「空间」,用于定义共享相同编码空间的一组域。
上图示例中的「Old」展示了在没有“域”和“空间”概念下的样本特征编码,所有特征从 1 开始编号;「New」展示了将 age 和 gender 分别放到 age 域和 gender 域后,两个域分别从 1 开始编码,互不影响。
Spark Feature 最终采用 TFRecords 作为训练样本的存储格式。
Bamboo:模型定义与训练
该组件主要为了实现可扩展、高效、简单快速的模型定义与训练。为此,在设计 Bamboo 时我们遵循以下原则:
1.layer 之间通过 tensor 进行交互,layer 的输入是 tensor,输出也是 tensor;
2.为了最大限度地提高离线与在线效率,没有采用太多高级 api,如 keras,大多数模型与组件基于 Tensorflow 底层 api 开发,并且根据 Tensorflow 官方的性能优化指南对代码进行优化;
3.提供 online-offline 的建模框架,复杂计算放到离线,在线只进行轻量计算,使得复杂模型更易上线;
4.封装数据加载、模型训练与导出、效果评估以及提供了各种辅助工具,用户只需要定义前向推理网络,同时封装了大量的常用 layer,模型定义更快捷。

Online Scorer:在线预测服务
Online Scorer的目标是提供一个统一,高效的在线推理服务,可以同时支持tensorflow,pytorch,xgboost等各种主流建模框架导出的模型。目前这块工作还在进行中,具体实现方案细节,我们放到后面的专题文章介绍。

以上就是美图自研机器学习框架的简要介绍,欢迎持续关注「美图数据技术团队」,后续将带来该平台的详细介绍。

时间:2018-10-18 23:27 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















