你应该知道的10种可视化技术
相比于浩如烟海的数据表格,大部分人还是更喜欢视觉资料,这一点已不足为奇。也是出于这个原因,人们通常才会在学术论文的前几页加上一张图表,并且清楚地标记上各种注释。
当数据科学家应用可视化技术后,数据的分布情况以及分析的重点将清楚而直观地展现在他们眼前。这种感觉异常奇妙!

数据可视化技术主要有两大功能:
将分析结果更加清晰地展现出来。
将数据有效组织起来,利于提出新的猜想,或引导某一项目下一步的走向。
本文将会介绍到十种可视化技术。以后,无论你是想让大家认可理论,还是为了规划项目的下一步计划,这些可视化方法都能帮助你分析数据。
1. 直方图
首先来了解一下直方图。通过直方图,可以纵观某个数值变量所有可能的值,以及其出现的频率。直方图看似简单,实际上功能却很强大。有时,直方图也被称为频数分布图。
从视觉效果上来说,需要画一个频率图,把相关变量排布在X轴上,而Y轴显示的则是每个值出现的频率。
例如,假设某个公司为了使自己的智能恒温器更加畅销,于是采取了一种营销策略,即根据顾客邮政编码的不同来提供相应的折扣。这时,通过绘制与恒温器折扣相关的直方图,人们就能更好地了解各个值的范围,以及它们各自出现的频率。

恒温器折扣直方图(单位:美元)
从上图可以发现,恒温器的折扣大约有半数介于100到120美元之间。而折扣低于60美元或者高于140美元的邮编,都只存在一小部分。
资料来源:https://ibm.box.com/s/6fltz5ilap8pbwzu2tt1yxil6ldosc9d
2. 条形图与饼状图
上文所讲的直方图通常用于处理数值变量,而本段所涉及的条形图与饼状图则主要适用于类别变量。如果要分析变量分布,并且这些变量的值又比较固定,比如只存在低、正常、高,是、否,或者常规驱动、电驱动、混合驱动等有限选项,那么这个时候最适合的选择就是条形图或者饼状图。
那么到底是选条形图还是饼状图呢?其实这两种方法都值得一试,然后再看看哪个的视觉效果会更好一些。但是在可能选项比较少的情况下,饼状图还是更胜一筹。
如果数据类别过多的话,无论是条形图还是饼状图,可视化的效果都不会太好。在这种情况下,可以考虑只对前几项最大值进行可视化处理。
在下面这个例子中,病人的血压情况同时在条形图和饼状图中表示出来,并且分为了三个类别,分别是低、正常和高。

病人血压条形图与饼状图
资料来源:https://ibm.box.com/s/rxixq3fto3bkmr7xi5t55pcbj9sb4der
3. 散点图与折线图
或许最简单的图莫过于散点图,因为它将数据展现在一个二维的笛卡尔坐标系中。散点图尤其适用于研究两个变量之间的关系,因为它能将这种相互关系更加直观地展现出来,以便我们进行研究。折线图其实也是散点图的一种,只不过它用一根线将所有的点连接了起来。如果变量Y的值是连续的,则常使用折线图。
例如,假设你想要去调查房价与建筑面积之间的关系,那么下面这幅散点图就可以帮到你。在这幅散点图上,Y轴表示房价,X轴表示建筑面积。同时,你要注意观察它是如何表示变量之间的线性关系的。总体上看来,建筑面积越大,房价越高。
可以通过颜色和尺寸的改变来扩展散点图的维度。比如我们可以根据每个房子卧室的数量来对点进行上色,从而就可以获得一个三维图。

如果想把散点图扩展为三维图或者是四维图,一个较为简便的方法就是改变气泡的颜色和大小。例如,如果根据每栋房子里房间数量的多少,来对上一幅散点图中的每一个气泡进行涂色,那么将得到三维的效果。
资料来源:https://ibm.box.com/s/n5m00r4ltcrx1e720d8mzw3et2d0vizy
4. 时间序列图
时间序列图也类似于散点图,只不过X轴上标注的是时间范围。在时间序列图上,所有的点连接成一条线,以提醒我们时间是连续的。
如果想要更加直观地研究某一数据随时间的变化趋势,时间序列图就是绝佳选择。因此,时间序列图在分析财务数据和传感器数据上应用得尤为普遍。
比如在下面这幅时间序列图中,Y轴所表示的就是在2015到2017年间特斯拉股票每日的收盘价。

2015年至2017年特斯拉股票收盘价时间序列图
资料来源:https://ibm.box.com/s/5oni1oeko2jej9x4er4zcu4k7cehvqp2
5. 关系图
如果你的目的是提出一个全面的猜想,那么关系图就非常合适,因为它能直观地展现出数据之间的关系。
假设你是一名在一家医疗公司工作的科学家,正在进行一个数据科学项目,该项目旨在让医生开处方的决策过程更加便捷化。那么,如果现在有四种药A、C、X和Y,并且医生只能给每个病人开其中一种药。而此时,你有一个数据集,其中包含病人开药的历史数据,病人的性别、血压和血糖等数据。
那么,如何解读关系图呢?在关系图中,数据集里的每一类数据都用一种不同的颜色表示,并且每条线的粗细程度代表着数据之间的相关性,也叫做频次计数。通过下面这个例子,可以进一步了解一下关系图。
从这幅处方关系图中,可以得出以下几点:
所有的高血压病人都开了A药。
所有的低血压高血脂病人都开了C药。
在开了X药的病人中,没有一个是高血压患者。
一旦获得了这些有效信息,你就可以提出一系列的假设,并且对新的领域进行研究。例如,机器学习分类器能够对A药、C药,或者是X药的使用做出准确的预测。然而,由于Y药与所有的特征值都有关联,因此在做出预测之前需要补充其他的特征值。

患者处方关系图
资料来源:https://ibm.box.com/s/rxixq3fto3bkmr7xi5t55pcbj9sb4der
6. 热图
另外一种能够把二维图升高一个维度的方法就是热图,这种方法同样很厉害并且色彩也比较丰富。在热图中会有一个矩阵或者地图显示,其上的颜色用来表示频率或者浓度。大部分的人都觉得热图非常直观,而且浅显易懂,因为图中颜色的浓度会显示出某些趋势以及需要特别关注的区域。
下面这幅热图展示的是在互联网电影数据库中,各电影名之间的编辑距离。某个电影名与其他电影名之间的编辑距离越远,它在图中显示的颜色就越深。比如就编辑距离而言,《超人》 (Superman) 就离《永远的蝙蝠侠》 (BatmanForever) 很远,离《超人2》 (Superman2) 很近。

电影名编辑距离热图
7. 地图
如果你的数据里包含经度和纬度的信息,或者其它通过地理位置来组织数据的方法,比如邮政编码、区域代码、县级数据或者机场数据等,那么在这个时候,绘制地图将会非常有助于对数据的可视化处理。
还记得之前在介绍直方图时举的那个有关于恒温器折扣的例子吗?回想一下,不同的地区所享受的折扣是不同的。由于这些数据里包含经度和纬度的信息,因此我们可以把折扣情况绘制在一张地图上。然后,只要在地图上添加一个色谱,即从表示最低折扣的蓝色一直到表示最高折扣的红色,就可以将数据全部绘制到一张美国地图上。
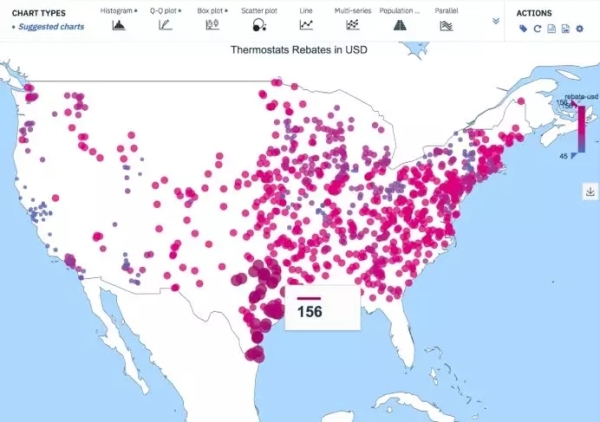
恒温器折扣地图
资料来源:https://ibm.box.com/s/6fltz5ilap8pbwzu2tt1yxil6ldosc9d
8. 词云
其实目前,我们所研究的大量数据都是以自由文本的形式出现的,并且这种文本也相对简单。在对此类数据进行第一遍处理时,可能本想更加直观地了解这些词在语料库中出现的频率。然而,不论是直方图还是饼状图,都对于这些文字类的数据显得力不从心,而更适合分析数字数据的频率。因此在这种情况下,可以求助于词云。
在处理自由文本数据时,首先应过滤掉所有的停用词,比如像“a”、“and”、“but”、“how”等,并且将所有的文本统一转为小写。如果要进一步整理数据,就要进行额外的工作,比如移除变音符、提取词干等。但需不需要进行这一步,则具体视目标而定。一旦数据整理好了以后,就可以立刻使用词云可视化技术,来分析语料库中哪些词出现得最普遍。
以下,我们根据Large Movie Reviews Dataset数据库绘制了两个词云,一个展示的是好评,另一个展示的则是差评。
数据库传送门:http://ai.stanford.edu/~amaas/data/sentiment/

电影好评词云

电影差评词云
9. 三维图
目前,为了分析三维数据,人们通常会选择在散点图的基础上增加一个维度,并且这种方式也正变得越来越普遍。这种三维图有许多优势,尤其是其交互性。因为通过使用旋转和缩放的功能,用户能够更加全面而深刻地分析数据。
以下这个例子中所展示的是一个二维的高斯概率密度函数,此外,还有一个可用于调整视角的控制面板。

二维高斯概率密度函数
资料来源:https://ibm.box.com/s/y0woc4hvk046v12yhlxdftkz32zw4po9
10. 高维图
在分析高维数据时,需要同时对四项、五项,甚至更多的相关数据进行可视化处理。因此,为了达到这个目的,可以利用上文所讲过的任何一个可视化技术,先构建一个二维或者三维模型。
例如,可以在上文的恒温器折扣地图中添加一个第三维度。具体来说,就是把地图上的每一个点都延伸为一条竖直线,用以表示该地区的平均能耗。通过以上步骤,获得一幅四维图,其中四个维度分别表示经度、纬度、折扣力度和平均能耗。
如果需要分析的数据维度比这还要更高,就需要先对数据进行降维处理。数据降维的方法主要有两种,即主成分分析法和t-SNE算法。
目前应用最为普遍的降维方法是主成分分析法。该方法通过找寻新的向量来进行降维,并且该向量必须尽可能多地反映数据原来的线性变化信息。如果数据间的线性关系足够强大,那么主成分分析法的降维效果就会非常明显,并且几乎不会发生信息的丢失。
相比之下,t-SNE算法就是一种非线性的降维方法。t-SNE算法在降低数据维度的同时,还会对原高维空间内数据点之间的距离进行保留。
来看看下面这幅图,图中的数据信息取样自MNIST手写数字数据库³。该数据库包含从0到9十个数字的数千种手写体图像,研究人员可以使用该数据库对他们的聚类算法和分类算法进行测试。数据库中,这些手写体图像的分辨率是784像素(28*28),然而通过t-SNE算法的应用,可以直接将这些784维的数据降至二维。

应用于MNIST手写数字数据库的t-SNE算法
资料来源:https://ibm.box.com/s/94e4q8askq82owlnr6qxerworm6cx2sp
至此,通过以上的讲解并且辅以实例,你一定对这十种应用最为广泛的可视化技术有了一定的了解。这篇文章中所出现的所有可视化图表都是在Watson Studio Desktop平台上制作完成的。当然,除了Watson Studio Desktop之外,还可以考虑使用其他的工具,比如R、Matplotlib、Seaborn、ggplot、Bokeh和plot.ly等,在这里就不列举更多的了。

时间:2019-07-25 23:01 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















