基于Kafka和ElasticSearch,领英是如何构建实时日志

及时有效地搜索日志是 SRE (Site Reliability Engineer) 日常工作的重要内容。LinkedIn 从使用 Splunk 到建立基于 ES 和 kafka 的日志分发、索引系统,为 SRE 提供了近似实时的搜索平台来检索超过 400 多个子系统的日志。在本文中,来自LinkedIn的李虓将和大家分享这套系统从无到有的一些技术架构经验。
今天和跟大家分享我们在用ElasticSearch和Kafka做日志分析的时候遇到的问题,系统怎么样一步一步演变成现在这个版本。你如果想拿ElasticSearch和Kafka来做日志分析的话,会有一些启发。全文主要包括以下几个Topic:
日志分析系统的基本需求;
LinkedIn的日志系统演进过程;
我们的经验和教训。
为什么要做日志分析系统?
首先,什么是日志?简单的说日志就是一个结构化的数据+时间戳。计算机开始日志就已经存在,从那时候就有各种各样的工具来帮我们分析、解析或者查找日志。
一开始做这个东西的时候,很多团队觉得不是很需要,工程师登录到服务器上面做一些cat或者grep和简单的表达式处理就够了,可以找到需要的信息。如果不够的话,比如在很多台机器上的话,有mssh、cssh等工具。
还不够的话,可以自己写工具,有一次我发现在我们的生产服务器上面,有一个SRE写了一套系统,从自己的台式机,做了一个ssh tunnel到实际的生产系统里面做了远程代码调用,远程把那些文件拿回来,这是一个一级的安全生产事故,是非常不负责任的事情,但是这也就暴露了我们确实有这个需求。
当我们有五万台服务器,五百多个微服务的时候,你不可能指望每个人都非常熟练的去解决这样的事情。开发或者运维经常会遇到这样的需求,比如拿某两个时间点之间的所有的日志,只需要看WARN或者ERROR或者FATAL的消息,并且有十几个错误是已知的,要忽略。
这个服务是跑在好几个数据中心几百台服务器上面,还需要关心有没有新的错误,这个错误是不是由于某个特定的用户造成的,或者某些特定的用户行为造成的,比如说他post了什么,或者request的长度超过一个固定长度;这个服务器上的错误信息有没有和其他服务器上的错误信息相关联。给我30分钟我有可能写出来一个四五行的grep命令去几百台服务器上把日志拉下来,但如果在凌晨三点钟,这就是一个不太可能的任务。
日志分析系统需要满足以下基本的要求:
对于重要的日志,满足索引,检索、排序、分类,并且提供一定程度的可视化、分析日志的功能;
可根据数据规模横向扩展。因为互联网的发展非常非常的快,我们希望找到一个解决方案,不要过了一年甚至半年,当服务器或者用户数量加倍以后,解决方案就完全不可用。需要找到一个方案,当用户数量加倍时,简单的加几台机器或者服务器就可以继续使用;
这套系统能够很轻易的扩展,因为很多公司已经有了很多的报警或者监控系统。可以方便的通过API或者通过扩展接入到已经有的监控、报警,或者其他系统里面。
还有一些其他扩展性的需求,包括日志采样,提高安全性、保护日志里面包含的信息,也是后面着重谈的一个问题。
LinkedIn日志系统演进回到四年前,从LinkedIn成立到2012年我们有一个系统叫Splunk,非常好用,只有一个问题,太贵了。2012年的时候,我们当时生产环境有三、四千台的服务器,续签第二年的合约时他们的报价是2000万美元一年。这实在是不可以接受的,并且那个时候是2012年,我们现在的服务器台数、用户请求数已经翻了差不多十倍,当时的价格如果是2000万,现在更多,因为它是根据数据量来算license的。
从2012年到2014年,因为我们当时决定不用Splunk,就进入了一个混沌期,这段时间非常痛苦,大家都有需求,但是没有人有方法,很多人开始搞自己的小动作,做些小工具。我之前看了一下内部工具库,里面有二、三十个用python或者shell写的小工具,这些小工具是用来找一个时间段内的log或者特定用户的log,但是有很大的浪费,很多工具重复的写,也非常难维护。
2014年到2015年这一年多的时间我们痛下决心,一定要做一套能够横跨LinkedIn所有log的系统,并且推广到整个LinkedIn。当时选择了ELK,它的优点就是:开源,发布周期非常快,当然也有缺点,它非常的新,所以有很多小毛病。
相信大家很多人已经知道ELK是什么——ElasticSearch、Logstash、Kibana。ElasticSearch就是基于Lucene的储存,索引,搜索引擎;Logstash是提供输入输出以及转换处理插件的日志标准化管道;Kibana提供可视化和查询ES的用户界面。
LinkedIn日志系统演进V1
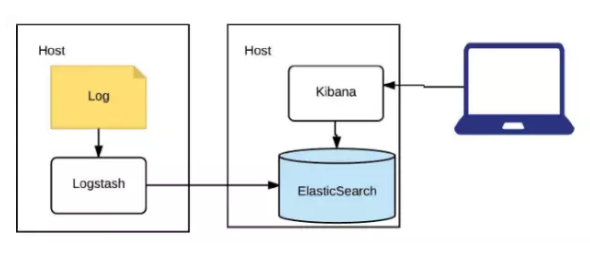
每个人花30分钟就可以在自己的电脑或者生产环境上搭一个这样的东西,Log通过Logstash读出来,放到ElasticSearch里,然后Kibana去读。这步做完以后其实就能达到非常好的效果。LinkedIn所有的业务群都会要求有一个异常面板,比如说支付系统业务群,它大概有十个左右不同的小服务。
当报警系统发现支付系统有了各种各样的问题之后,我们第一步就是到异常面板来看Log里面有没有什么东西,可以根据时间线上看,有没有哪些新的服务在近期有了新的log或者error log数量不一样。并且它会根据不同的exception/java stack拿出来做count,这也给分析带来很大的帮助,还可以写出很多复杂的query。
第一个版本非常简单,我们只把它应用到了一两个非常关键的系统上。这套系统做完之后我们做了一个对比,平均故障解决时间从以前的五十几分钟缩短到小于30分钟。我们的线上系统一般最快会花5到10分钟才有一个不是很关键的警报出来,如果能很快发现问题在哪里,解决这个问题,比如说一个简单的rollback操作,在几百台机器上也会花5到10分钟的时间,真正留给人根据log去判断问题在哪里的时间也只有短短的5到10分钟。
如果不是有一个异常面板能看到所有的信息,比如有没有哪个服务器的异常比其他服务器多,有没有一个异常是突然今天出了很多次的,或者有没有一个服务器今天出了很多的异常,最起码要花二十到三十分钟的时间手工的看log。
第一个版本有几个问题,第一是Logstash Agent的维护不是很理想,Logstash是基于Ruby的,启动它就要有几十兆内存被jvm吃掉,我们想避免在每个机器上都要起一个Logstash。并且在我们使用过程中Logstash非常不稳定,莫名其妙就死掉了,还需要一个守护进程守护它。第二个是log标准化,也是非常头疼的问题。
第一个Logstash Agent的问题通过引入Kafka解决,引入Kafka后不需要每个host上有agent。
LinkedIn内部有专门的SRE团队维护Kafka,很便宜,不需要花钱去维护。对于Log标准化,我们花了非常多的时间看,LinkedIn有99%的服务都是java service,有15种以上log,最重要的是access log和application log。我们做的一件事情是通过java Container logger标准化直接写入Kafka。有的程序直接写到kafka,不上磁盘,有的程序还要同时写到磁盘里面,这是可配置的。
这些是通过LinkedIn standard container一起rollout到所有的service上。开发人员什么都不用管,只要在程序里写logger.info/logger.error,那些信息就会直接进到Kafka。对于程序日志,默认警告以上的级别进入Kafka,可以在线通过jmx控制。对于访问日志,我们有10%采样,可以通过ATS入口动态控制。
LinkedIn日志系统演进V2
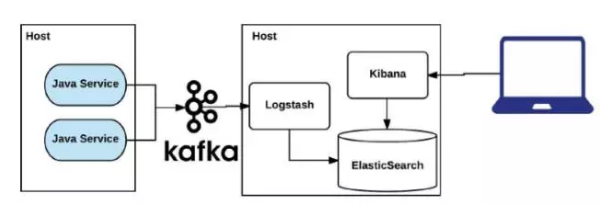
这是第二个版本,可以看到在生产环境的Java service那边,Host上已经没有Logstash,所有的log直接写入Kafka,Logstash从Kafka里消费这些日志,写到ElasticSearch里面去。
第二个版本还会出现一些问题,比如说一个服务出现问题的时候会影响整个ELK cluster。我们出现过这样的情况,一个团队写了一个新的服务,把所有的log的级别都定义成error,整个ElasticSearch就被它冲垮了。很多时候还会出现网络饱和的情况。
很简单,第二步非常简单的决定就是把它进行拆分优化:
首先按照业务功能拆分ELK cluster,比如说负责支付的,跟钱有关的系统用一个集群;所有跟用户登陆有关的系统,安全有关的系统用一个集群;
将Logstash和ElasticSearch分开运行。ElasticSearch是磁盘密集的操作,Logstash是CPU密集的操作,我们当时想把他们放到一个物理机上,但是试下来相互影响还是挺大的,所以决定把Logstash跟其他的系统混用,与ElasticSearch分开运行;
对于每个Kafka话题,Logstash数量不少于话题partition数量。LinkedIn有500多个服务,每个服务会产生访问日志、程序日志两个Kafka topic。Logstash消费Kafka的时候,如果consumer数量少于partition数量,会触发Kafka一个隐藏的漏洞,导致Kafka partition不均匀,出现各种诡异的问题。我们的建议是,一般情况下,每个topic有四到八个partition,然后根据情况设置相应数量的Logstash。
LinkedIn日志系统演进V3
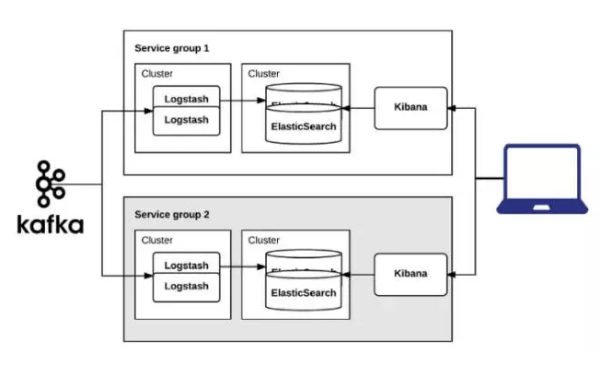
根据业务需求拆分,我们拆出来20几个这样的相同的集群,这个版本,还有一些问题。首先是跨业务分组集群的查询,虽然很多的时候,一个问题在一个业务分组里面就能找到,但是还有很多的时候要跨到另外一个集群里面才能找到问题到底是从哪开始的。
第二,千万不要跨数据中心做ElasticSearch的集群,非常非常差,根本跑不起来。即使两个数据中心非常近这样做也不好,尤其当数据量上来之后,会有一些非常诡异的问题。数据量非常大的ElasticSearch集群我们会要求它全部在一个机架上,如果有一个服务器在另一个机架上都会出现timeout的问题。
为了解决刚刚说的问题,我们引入Tribe,用下来的感觉可以用,但是这明显不是一个他们支持的功能。Tribe理念很好,但是它不支持分层,我们需要两种不同的Tribe,首先要能跨业务分组,还要跨数据中心。
最好的情况是做一个分层的结构,数据中心在最外面,业务分组在最里面,但是从设计理念上是另外一个概念,所以不行。只能退而求其次,在一个数据中心里面会有跨所有业务分组的一个Tribe,还会对相同的业务分组有一个跨数据中心的Tribe,有两个不同类型的Tribe进行查询。
LinkedIn日志系统演进V4
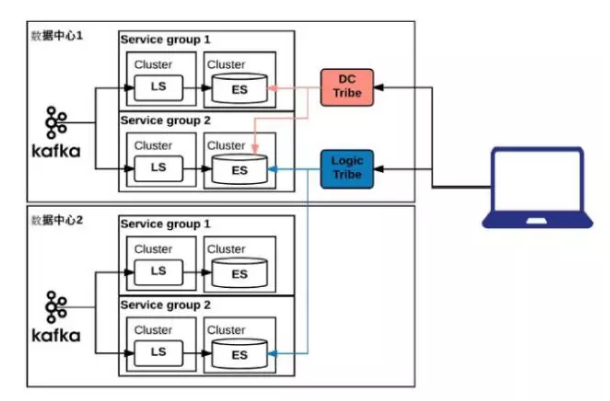
到这一步,基本上功能实现的差不多了,就开始慢慢的把500多个服务的日志打到Kafka里面,大概花了一两个月,发现consume跟不上,遇到了性能瓶颈。用ElasticSearch超过50或者100台服务器,就会遇到很多这样的瓶颈。我们花了三个月的时间,做了各种性能调优。
这一步算是最后一步,首先理解了一下自己的业务逻辑,我们要做的事情非常明白,非常单一,就是需要实时的,或者准实时的log来做在线的trouble shooting,基本上不会用到14天以前的数据,保留14天以前的数据就是为了看两周的周期而已。
今天的问题都解决不完,根本没有时间考虑几个月之前的问题,实际的业务状态是24小时之内的日志查询的最多,14天以前用的非常少,查询速度要求在15秒之内,超过30秒就timeout了。索引速度30秒以内可以接受,超过5分钟会触发警报。
LinkedIn日志系统演进V5
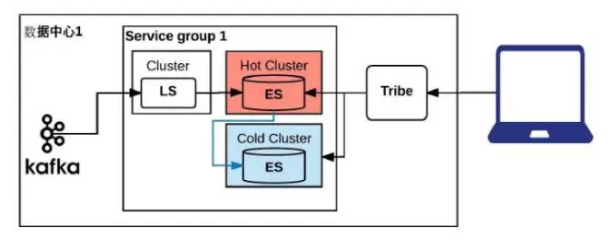
采用冷热分区的方式解决这个问题,我们测试了很多种不同的硬件,最后选定了在非常重要和数据量很大的集群上用ssd做热索引,24小时之内的索引全部上到SSD机器上,超过24小时就挪到普通的机器上。相当于在集群里边,有一个热的Cluster,数据全面走到热的cluster里面,24小时以后,会被挪到冷的cluster。做了这个之后,系统变得比较稳定,功能也正常,内部会根据需求保留7到14天的数据。
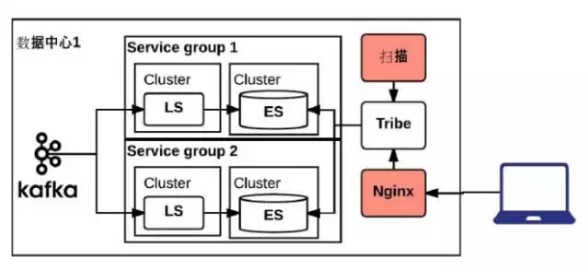
这步之后,我们把它推广到LinkedIn整个公司,第二天我接到法务和安全部的电话。当我们做了一个非常容易的系统,把所有的log展现给所有人的时候,如果大家能很轻易的把4亿用户的用户名、密码、邮箱等信息搜出来,这个事情就非常严重,所以我们又做了几个调整。
第一个是定期扫描所有的ES,根据特定的关键字来防止敏感信息进入日志,如果进入马上报警。还有用户隐私的问题,所有Elasticsearch的查询记录同样送入Kafka,并对敏感业务部门的访问进行隔离,所有访问日志定期审核。我们的做法是在前面加一个Nginx,在nginx上可以做访问控制,把用户所有的访问日志全部送回Kafka做定期审核,有一个扫描进程定期的扫描各种各样的关键字。
LinkedIn日志系统演进现状
这是我们现在生产系统里的状态,有20多个针对不同业务模块的ELK集群,1000+服务器,主要都是Elasticsearch。1分钟之内生产系统发生的log我们这边就可以搜索,所有的log保留7到14天。现在大概有500亿的索引文档,500到800T,之前测试时推到1500到2000T都是可以工作的。
因为我们是500多个service,20多个集群,没有办法很好的维护这么多集群,所以是每个业务模块的SRE团队维护自己的Elasticserach集群。Virtual Team模式确保ELK的及时更新。还有一点比较关键,需要保证你的ES不会被没有授权的用户访问,默认的情况下是不接受SSL连接的,SearchGuard和Sheild这两种解决方式都是可以解决这个问题的。
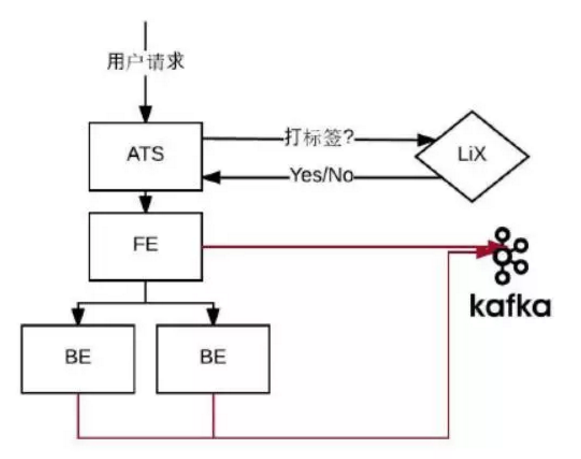
我想着重提一下采样方式,这个是比较有意思的,也是比较通用的方式。采样方式是10%+特定的用户,为什么要这么做?我们调过不同的比例,发现不影响,如果有问题,10%的采样就能发现。为什么还要特定用户呢?很多时候,有一些active的用户会经常给你报错,给你反馈意见,需要及时去看到底发生了什么事情。
对LinkedIn来说有大概百分之零点几的power user在网站上非常活跃,做很多事情,我们需要把他们的log加到sample里。所有的用户请求,都是通过Apache Traffic Server进入数据中心,在这层它会去访问LiX,询问是否要对当前用户打标签,如果打了标签就把这个标签放在InvocationContext里面。
从前台到后台所有的服务器只要touch到这个request,都会在InvocationContext里看到一个requestID。通过java container的bydefault得到requestID,把那条访问的日志发到Kafka里面,通过这样的方式做成sample。
这样做有两点好处,一点是如果有什么问题,只需要把他的memberID或者requestID拿到最上面一层Tribe里面,系统就会出现关于这条request的所有service的log。99.9%的情况可以一目了然的知道哪里出了问题。做微服务的大家都知道,dependence非常乱,我们LinkedIn的情况,一个request会touch二三十个service。所以说有这样一个方式是非常重要的。
日常运维之坑我想聊一下我们遇到的几个坑,ES集群的默认名字是大坑,如果不改集群名字就把它放在自己的电脑上或者测试系统上跑,一旦相同子网的人加了一个新的node也没有改名字,就会自动加到你的集群里面。不管怎么样一定要改你的集群名字。
Master、Data、Client节点不要混用,使用单ES节点;JVM不要allocate超过30G的heap,我们测试发现30G左右的heap可以达到最好的performance,如果超过30G就没有办法完全使用;JVM版本的兼容性也是一个超级大的坑,它不是最新的兼容,也不是哪个版本以后,或者以前兼容,是有几个版本兼容,再几个版本不兼容,再几个版本兼容。有一些兼容性的问题一定要注意。
日常运维之硬件讲一下刚才已经提到的硬件的选择,要根据数据量,业务的情况,索引和查询速度的要求决定,像我们的要求是一定要索引快,因为要做实时的故障排查,数据的类型我们只做两个,一个是访问log,一个是application log,这些决定了我们使用的硬件是12核/64G/2x1TB的硬盘,有八九百台都是这样的配置。
有一小部分是数据量非常大但是对查询的速度要求不是很高,比如做自动查询的那套,我们会把数据丢到JBODs里面,索引速度优先考虑的话,会用100台左右的SSD。
日常运维之集群集群没有magic number,必须要用实际的生产数据,一遍一遍试,才能试出来用什么样的配置能达到最好的效果,这几个是我们的learning:
横向扩展,不要纵向扩展,不要试图用更大的memory或者最快的CPU,不会有太大的效果,我们大概测过四五个版本,基本上没怎么成功;
每个shard不要超过50G,只要超过50G我们的shard就会莫名其妙的失联;
关闭冗余,我们把replication关了是为了更快。关了之后如果出现硬件故障,从Kafka那边读,数据很快就能回来;
每天建新的索引,有一个集群因为数据量非常大,会做每个小时的索引,二三个数据量比较小的集群每周做一个索引;
只分析必要字段,IP字段、设备版本,这些字段完全没有必要做分析,只要能整字段查找就行了,把它关掉,可以省很多的空间,index速度也会快很多。
日常运维之工具还有就是一些工具,刚刚提到主动扫描敏感信息的就是一个script在后台根据一些关键字扫描敏感信息;结合警报系统,相信每个公司都有自己的警报系统,ElasticAlert是一个开源的解决方案,我们自己也有内建的,根据读出来的信息的关键字做警报;循环删除index用的Curator;系统健康状态监控是自己做的监控系统,官方的Marvel也很好用。
提高代码质量做完这套系统以后,我们并不是完全被动的状态,只能用这套系统来做故障排查,我们发现这套系统里面有些指标可以很好的反映开发人员的代码的质量。
请求数/日志总行数,对于每个service都不一样,但是大概有一个区间,如果出了这个区间,可能这个service就有一些问题;
请求数量/错误(异常)行数,这个也有一个区间,我们这边的区间是1000个请求,大概产生2000到5000行的日志,500到3000行的异常数量,这个是我们可以接受的,经常会有service超出这个范围10倍,通过这个就能发现异常有没有处理。
通过这些发现一些有意思的metric返回给开发人员,帮助他们提高代码的质量,这是一个比较有意思的发现。国外和国内大家做的东西很多很像,遇到的问题也很像,希望能给大家一些启发。
文:李虓 LinkedIn SRE 团队高级技术经理
来源:InfoQ

时间:2018-10-09 22:55 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















