一篇文章全面解析大数据批处理框架Spring Batch
如今微服务架构讨论的如火如荼。但在企业架构里除了大量的OLTP交易外,还存在海量的批处理交易。在诸如银行的金融机构中,每天有3-4万笔的批处理作业需要处理。针对OLTP,业界有大量的开源框架、优秀的架构设计给予支撑;但批处理领域的框架确凤毛麟角。是时候和我们一起来了解下批处理的世界哪些优秀的框架和设计了,今天我将以Spring Batch为例,和大家一起探秘批处理的世界。
- 初识批处理典型场景
- 探秘领域模型及关键架构
- 实现作业健壮性与扩展性
- 批处理框架的不足与增强
批处理典型业务场景
对账是典型的批处理业务处理场景,各个金融机构的往来业务和跨主机系统的业务都会涉及到对账的过程,如大小额支付、银联交易、人行往来、现金管理、POS业务、ATM业务、证券公司资金账户、证券公司与证券结算公司。
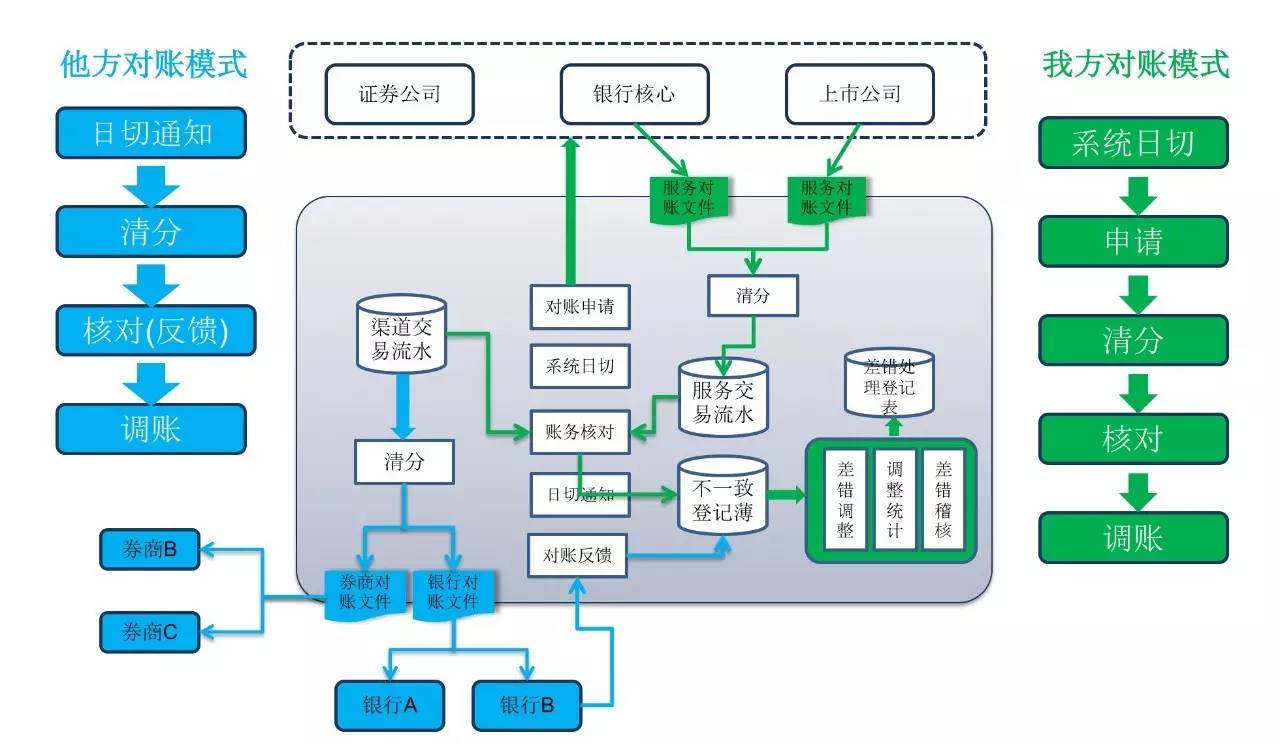
下面是某行网银的部分日终跑批实例场景需求。

涉及到的需求点包括:
- 批量的每个单元都需要错误处理和回退;
- 每个单元在不同平台中运行;
- 需要有分支选择;
- 每个单元需要监控和获取单元处理日志;
- 提供多种触发规则,按日期,日历,周期触发;
除此之外典型的批处理适用于如下的业务场景:
- 定期提交批处理任务(日终处理)
- 并行批处理:并行处理任务
- 企业消息驱动处理
- 大规模的并行处理
- 手动或定时重启
- 按顺序处理依赖的任务(可扩展为工作流驱动的批处理)
- 部分处理:忽略记录(例如在回滚时)
- 完整的批处理事务
与OLTP类型交易不同,批处理作业两个典型特征是批量执行与自动执行(需要无人值守):前者能够处理大批量数据的导入、导出和业务逻辑计算;后者无需人工干预,能够自动化执行批量任务。

在关注其基本功能之外,还需要关注如下的几点:
- 健壮性:不会因为无效数据或错误数据导致程序崩溃;
- 可靠性:通过跟踪、监控、日志及相关的处理策略(重试、跳过、重启)实现批作业的可靠执行;
- 扩展性:通过并发或者并行技术实现应用的纵向和横向扩展,满足海量数据处理的性能需求;
苦于业界真的缺少比较好的批处理框架,Spring Batch是业界目前为数不多的优秀批处理框架(Java语言开发),SpringSource和Accenture(埃森哲)共同贡献了智慧。

Accenture在批处理架构上有着丰富的工业级别的经验,贡献了之前专用的批处理体系框架(这些框架历经数十年研发和使用,为Spring Batch提供了大量的参考经验)。
SpringSource则有着深刻的技术认知和Spring框架编程模型,同时借鉴了JCL(Job Control Language)和COBOL的语言特性。2013年JSR-352将批处理纳入规范体系,并被包含在了JEE7之中。这意味着,所有的JEE7应用服务器都会有批处理的能力,目前第一个实现此规范的应用服务器是Glassfish 4。当然也可以在Java SE中使用。

但最为关键的一点是:JSR-352规范大量借鉴了Spring Batch框架的设计思路,从上图中的核心模型和概念中可以看出究竟,核心的概念模型完全一致。完整的JSR-252规范可以从https://jcp.org/aboutJava/communityprocess/final/jsr352/index.html下载。
通过Spring Batch框架可以构建出轻量级的健壮的并行处理应用,支持事务、并发、流程、监控、纵向和横向扩展,提供统一的接口管理和任务管理。

框架提供了诸如以下的核心能力,让大家更关注在业务处理上。更是提供了如下的丰富能力:
- 明确分离批处理的执行环境和应用
- 将通用核心的服务以接口形式提供
- 提供“开箱即用” 的简单的默认的核心执行接口
- 提供Spring框架中配置、自定义、和扩展服务
- 所有默认实现的核心服务能够容易的被扩展与替换,不会影响基础层
- 提供一个简单的部署模式,使用Maven进行编译
批处理关键领域模型及关键架构
先来个Hello World示例,一个典型的批处理作业。

典型的一个作业分为3部分:作业读、作业处理、作业写,也是典型的三步式架构。整个批处理框架基本上围绕Read、Process、Writer来处理。除此之外,框架提供了作业调度器、作业仓库(用以存放Job的元数据信息,支持内存、DB两种模式)。
完整的领域概念模型参加下图:

Job Launcher(作业调度器)是Spring Batch框架基础设施层提供的运行Job的能力。通过给定的Job名称和作Job Parameters,可以通过Job Launcher执行Job。
通过Job Launcher可以在Java程序中调用批处理任务,也可以在通过命令行或者其它框架(如定时调度框架Quartz)中调用批处理任务。
Job Repository来存储Job执行期的元数据(这里的元数据是指Job Instance、Job Execution、Job Parameters、Step Execution、Execution Context等数据),并提供两种默认实现。
一种是存放在内存中;另一种将元数据存放在数据库中。通过将元数据存放在数据库中,可以随时监控批处理Job的执行状态。Job执行结果是成功还是失败,并且使得在Job失败的情况下重新启动Job成为可能。Step表示作业中的一个完整步骤,一个Job可以有一个或者多个Step组成。
批处理框架运行期的模型也非常简单:

Job Instance(作业实例)是一个运行期的概念,Job每执行一次都会涉及到一个Job Instance。
Job Instance来源可能有两种:一种是根据设置的Job Parameters从Job Repository(作业仓库)中获取一个;如果根据Job Parameters从Job Repository没有获取Job Instance,则新创建一个新的Job Instance。
Job Execution表示Job执行的句柄,一次Job的执行可能成功也可能失败。只有Job执行成功后,对应的Job Instance才会被完成。因此在Job执行失败的情况下,会有一个Job Instance对应多个Job Execution的场景发生。
总结下批处理的典型概念模型,其设计非常精简的十个概念,完整支撑了整个框架。

Job提供的核心能力包括作业的抽象与继承,类似面向对象中的概念。对于执行异常的作业,提供重启的能力。

框架在Job层面,同样提供了作业编排的概念,包括顺序、条件、并行作业编排。
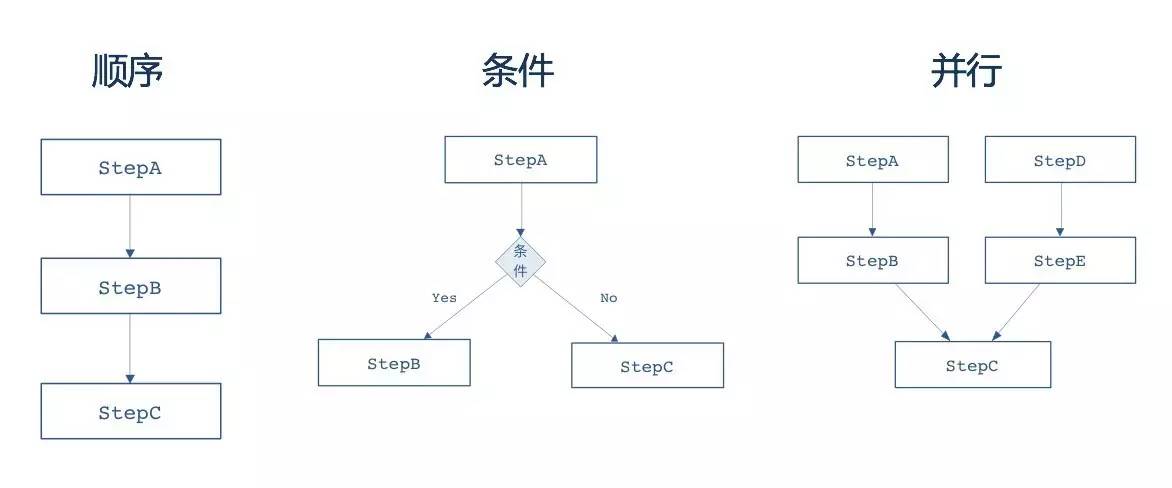
在一个Job中配置多个Step。不同的Step间可以顺序执行,也可以按照不同的条件有选择的执行(条件通常使用Step的退出状态决定),通过next元素或者decision元素来定义跳转规则;
为了提高多个Step的执行效率,框架提供了Step并行执行的能力(使用split进行声明,通常该情况下需要Step之间没有任何的依赖关系,否则容易引起业务上的错误)。Step包含了一个实际运行的批处理任务中的所有必需的信息,其实现可以是非常简单的业务实现,也可以是非常复杂的业务处理,Step的复杂程度通常是业务决定的。
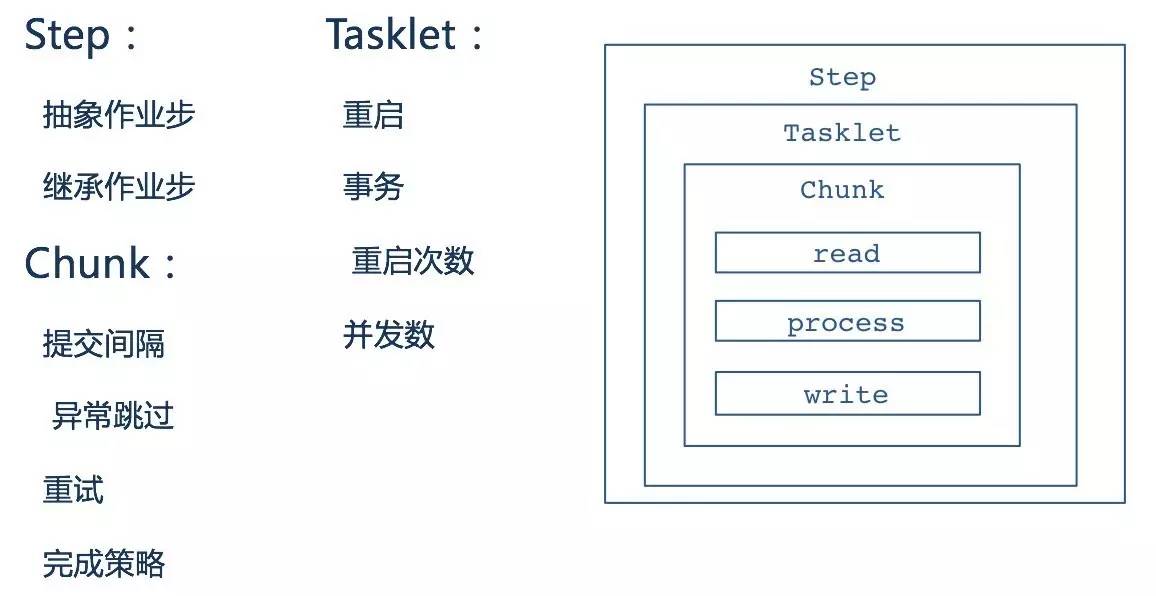
每个Step由ItemReader、ItemProcessor、ItemWriter组成,当然根据不同的业务需求,ItemProcessor可以做适当的精简。同时框架提供了大量的ItemReader、ItemWriter的实现,提供了对FlatFile、XML、Json、DataBase、Message等多种数据类型的支持。
框架还为Step提供了重启、事务、重启次数、并发数;以及提交间隔、异常跳过、重试、完成策略等能力。基于Step的灵活配置,可以完成常见的业务功能需求。其中三步走(Read、Processor、Writer)是批处理中的经典抽象。

作为面向批的处理,在Step层提供了多次读、处理,一次提交的能力。
在Chunk的操作中,可以通过属性commit-interval设置read多少条记录后进行一次提交。通过设置commit-interval的间隔值,减少提交频次,降低资源使用率。Step的每一次提交作为一个完整的事务存在。默认采用Spring提供的声明式事务管理模式,事务编排非常方便。如下是一个声明事务的示例:

框架对于事务的支持能力包括:
- Chunk支持事务管理,通过commit-interval设置每次提交的记录数;
- 支持对每个Tasklet设置细粒度的事务配置:隔离界别、传播行为、超时;
- 支持rollback和no rollback,通过skippable-exception-classes和no-rollback-exception-classes进行支撑;
- 支持JMS Queue的事务级别配置;
另外,在框架资深的模型抽象方面,Spring Batch也做了极为精简的抽象。

仅仅使用六张业务表存储了所有的元数据信息(包括Job、Step的实例,上下文,执行器信息,为后续的监控、重启、重试、状态恢复等提供了可能)。
- BATCH_JOB_INSTANCE:作业实例表,用于存放Job的实例信息
- BATCH_JOB_EXECUTION_PARAMS:作业参数表,用于存放每个Job执行时候的参数信息,该参数实际对应Job实例的。
- BATCH_JOB_EXECUTION:作业执行器表,用于存放当前作业的执行信息,比如创建时间,执行开始时间,执行结束时间,执行的那个Job实例,执行状态等。
- BATCH_JOB_EXECUTION_CONTEXT:作业执行上下文表,用于存放作业执行器上下文的信息。
- BATCH_STEP_EXECUTION:作业步执行器表,用于存放每个Step执行器的信息,比如作业步开始执行时间,执行完成时间,执行状态,读写次数,跳过次数等信息。
- BATCH_STEP_EXECUTION_CONTEXT:作业步执行上下文表,用于存放每个作业步上下文的信息。

时间:2018-10-10 22:41 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















