Hadoop大数据平台架构与实践
一、什么是Apache Hadoop?
1.1 定义和特性
可靠的、可扩展的、分布式计算开源软件。
Apache Hadoop软件库是一个框架,允许使用简单的编程模型,在计算机集群分布式地处理大型数据集。
它可以从单个服务器扩展到数千台机器,每个机器都提供本地计算和存储。
每一台计算机都容易出现故障,库本身的目的是检测和处理应用层的故障,因此在一组计算机上提供高可用性服务,而不是依靠硬件来提供高可用性。
1.2 主要模块:
Hadoop Distributed File System(HDFS): 一个分布式文件系统,它提供对应用程序数据的高吞吐量访问。
Hadoop YARN: 作业调度和集群资源管理的框架。
Hadoop MapReduce: 基于YARN的大型数据集并行处理系统。
二、Hadoop安装(以hadoop-1.2.1为例)
2.1 准备条件
Linux操作系统
安装JDK以及配置相关环境变量
下载Hadoop安装包,如:hadoop-1.2.1.tar.gz(官网下载地址:http://hadoop.apache.org/releases.html)
2.2 安装
将hadoop-1.2.1.tar.gz解压到指定目录,如:/opt/hadoop-1.2.1/
2.3 配置hadoop环境变量
在/etc/profile中配置如下信息:

2.4 修改四个配置文件
这四个配置文件均在/opt/hadoop-1.2.1/conf/目录下。
(a)修改hadoop-env.sh,设置JAVA_HOME:

(b)修改core-site.xml,设置hadoop.tmp.dir,dfs.name.dir,fs.default.name:
©修改mapred-site.xml,设置mapred.job.tracker:

(d)修改hdfs-site.xml,设置dfs.data.dir:

2.5 格式化
执行命令:

正确执行的结果如下所示:
2.6 启动

2.7 查看当前运行的java进程
在Terminal输入命令,出现如下结果表示hadoop安装成功:

三、HDFS简介
3.1 HDFS基本概念
HDFS设计架构

块(Block):
HDFS的文件被分成块进行存储
HDFS块的默认大小为64MB
块是文件存储处理的逻辑单元
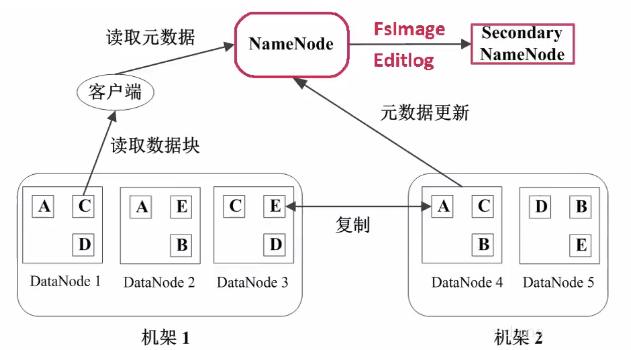
管理节点(NameNode),存放文件元数据:
文件与数据块的映射表
数据块与数据节点的映射表
DataNode:
DataNode是HDFS的工作节点
存放数据块
3.2 数据管理策略与容错
数据块副本:每个数据块至少3个副本,分布在两个机架内的多个节点
心跳检测:DataNode定期向NameNode发送心跳消息

二级NameNode:二级NameNode定期同步元数据映像文件和修改日志,NameNode发生故障时,二级NameNode替换为主NameNode
3.3 HDFS中文件的读写操作
HDFS读取文件的流程

HDFS写入文件的流程

3.4 HDFS的特点
数据冗余,硬件容错
流式的数据访问(一次写入、多次读取)
适合存储大文件
适用性和局限性
适合数据批量读写,吞吐量高
不适合交互式应用,低延迟很难满足
适合一次写入多次读取,顺序读写
不支持多用户并发写相同文件
3.5 HDFS使用
HDFS命令行操作:

四、MapReduce简介
4.1 MapReduce的原理
分而治之,一个大任务分成多个小的子任务(map),并行执行后,合并结果(reduce)

4.2 MapReduce的运行流程
基本概念
Job(作业) & Task(任务)
一个Job可以分成多个Task(MapTask & ReduceTask)
JobTracker(作业管理节点)
客户端提交Job,JobTracker将其放入候选队列中,在适当的时候进行调度,将Job拆分成多个MapTask和ReduceTask,分发给TaskTracker执行。JobTracker的角色:
作业调度
分配任务、监控任务执行进度
监控TaskTracker的状态
TaskTracker(任务管理节点)
通常TaskTracker和HDFS的DataNode属于同一组物理节点,实现了移动计算代替移动数据,保证读取数据开销最小。TaskTracker的角色:
执行任务
汇报任务状态
MapReduce的体系结构

MapReduce作业执行过程

MapReduce的容错机制
重复执行
默认为最多4次后放弃
推测执行
原因:所有Map端运算完成,才开始执行Reduce端。
作用:保证整个任务的计算,不会因为某一两个TaskTracker的故障,导致整个任务执行效率很低。
五、YARN - Hadoop 资源管理器
YARN的基本思想是将资源管理和作业调度/监控的功能拆分到不同的守护进程。这种思想需要有一个全局的资源管理器(RM)和(每个应用程序都要有的)应用程序管理器(AM)。
资源管理器(RM)和节点管理器(NodeManager)形成了数据计算框架。资源管理器(RM)是在系统中所有应用程序间仲裁资源的最终权威。节点管理器(NodeManager)是每台机器的框架代理,负责容器的管理,监控他们的资源使用情况(cpu、内存、磁盘、网络),并向资源管理器(RM)/调度器报告该情况。
每个应用程序的应用程序管理器(AM)实际上是一个特定的框架的库,它的任务是与资源管理器(RM)协商资源,并与节点管理器(NodeManager)一起工作来执行和监视任务。
资源管理器(RM)有两个主要组件:调度程序和应用程序管理器(AM)。
调度程序负责将资源分配给各种运行的应用程序。调度程序是纯粹的调度器,因为它不执行应用程序的状态监视或跟踪。另外,它也不能保证重新启动失败的任务,无论是由于应用程序失败还是硬件故障。
应用程序管理器(AM)负责接收提交的工作,协商执行应用程序的第一个容器,并并提供在失败时重新启动应用程序管理器(AM)容器的服务。每个应用程序管理器(AM)负责从调度程序中协商适当的资源容器,跟踪它们的状态并监视进程。
YARN 还支持资源预定的概念,保留资源以确保重要工作的可预见性执行。预订系统会对资源进行跟踪,对预订进行控制,并动态地指导底层的调度程序,以确保预订是满的。
 Hadoop官网:http://hadoop.apache.org
Hadoop官网:http://hadoop.apache.org
作者:Jochen_M
来源:CSDN

时间:2018-11-25 13:25 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















