一个 22 万张 NSFW 图片的鉴黄数据集?我有个大胆
如果你想训练一个内容审核系统过滤不合适的信息,或用 GAN 做一些大胆的新想法,那么数据集是必不可少的。例如图像鉴黄,我们需要使用卷积神经网络训练一个分类器,以区分正常图像与限制级图像。但限制级的图像很难收集,也很少会开源。因此最近有开发者在 GitHub 上开源了一份 NSFW 图像数据集,这是不是你们想要的?
内容审核在很多领域都有非常重要的作用,它不仅需要通过分类器识别图像或其它数据不适合展示,同时还能结合语义分割模型对这些限制级图像进行处理(Mask 掉敏感部分)。这样在不过多影响内容的情况下去除掉不合适的信息。开发者 alexkimxyz 构建的这个项目大概收集了 20 多万张敏感图像,且通过 URL 的形式展示了 GitHub 中。
项目地址:https://github.com/alexkimxyz/nsfw_data_scrapper
这 20 万多张图像大概分为以下 5 个类别,它们可以用 CNN 训练不同的分类器。这里我们就保留 GitHub 中的原描述了:

其中每一个类别都是一个 Text 文本,文本中的每一行都对应一个 URL,所以读取并下载都非常方便,自己写也就几行代码。如下简单展示了 sexy 类别下文本与图像:

此外值得注意的是,有少量图像 URL 是失效的,因此在处理的过程中需要把这些情况考虑进去。一般如果 URL 是失效的,它会返回一张 161×81 的声明图像。
当然,作者同样提供了获取 URL 和下载图像的脚本,我们只需要运行就行了。目前,这些脚本仅在 Ubuntu 16.04 Linux 发行版本中进行了测试。
以下是重要脚本(位于 scripts 目录下)及它们的作用:
1_get_urls.sh:遍历 scripts / source_urls 下的文本文件,下载上述 5 个类别中每个类别的图像 URL。Ripme 应用程序执行所有关键部分。源 URL 主要是链接到各种 subreddits,但可以是 Ripme 支持的任何网站。注意:作者已经运行了此脚本,其输出位于 raw_data 目录中。除非在 scripts / source_urls 下编辑文件,否则无需重新运行。
2_download_from_urls.sh:下载 raw_data 目录中的文本文件中找到的 URL 的实际图像。
5_create_train.sh:创建 data/train 目录并从 raw_data 将所有 * .jpg 和 * .jpeg 文件复制到其中。并删除损坏的图像。
6_create_test.sh:创建 data/test 目录,并从 data / trainto 为每个类随机移动 N = 2000 个文件(如果需要不同的训练 / 测试分割,则在脚本内更改此数字)到 data / test。或者,可以多次运行它,每次它将从 data/train 到 data/test 将每个类别移动 N 个图像。
注意运行 get_urls.sh 后,生成的 URL 文本文件会覆盖 raw_data 下已有的文本文件。所以在复制 GitHub 项目后,我们也可以直接运行 2_download_from_urls.sh 从已有 raw_data 文件下载图像。
环境配置
Python3 环境:conda env create -f environment.yml
Java 运行时环境(Ubuntu linux):sudo apt-get install default-jre
Linux 命令行工具:wget, convert (imagemagick 工具套件), rsync, shuf
怎么运行
将工作目录转到 scripts,并按文件名中的数字指示的顺序执行每个脚本,例如:
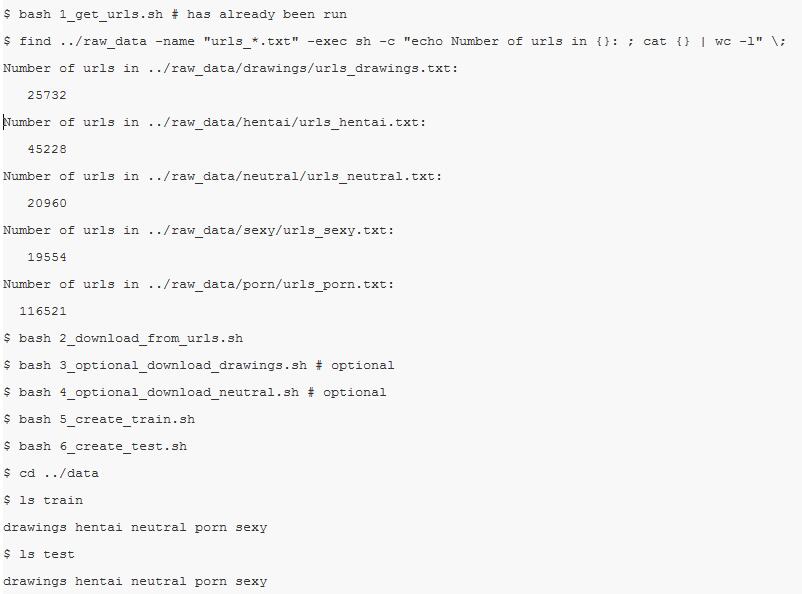
如上所示为脚本的执行方法,五类一共 227995 张敏感图像。这个脚本同样会把它们分割为训练集与测试集,因此直接利用它们实现 5 类别的分类任务会很简单。当然如果我们需要用于其它的任务,就没有必要直接分割了。
使用简单的卷积神经网络直接实现分类任务可以达到 91% 的准确率,这已经非常高了,因为敏感数据手动分为 5 类本来就有一些模糊性存在。以下展示了在测试集上,5 分类任务的混淆矩阵:

其中对角线表示正确预测的样本数,其它为误分类样本数。这个分类任务至少说明了 5 类别是有区分度的,不论我们用于正常内容与敏感内容的二分类,还是使用 GAN 做一些新奇的模型,类别都是很有区分度的特征。
最后,各位请怀着敬畏之心严肃使用,且仅供研究使用(不要举报)……

时间:2019-01-14 23:26 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















