机器学习进阶笔记之六 | 深入理解Fast Neural Styl

引言
TensorFlow是Google基于DistBelief进行研发的第二代人工智能学习系统,被广泛用于语音识别或图像识别等多项机器深度学习领域。其命名来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow代表着张量从图象的一端流动到另一端计算过程,是将复杂的数据结构传输至人工智能神经网中进行分析和处理的过程。
TensorFlow完全开源,任何人都可以使用。可在小到一部智能手机、大到数千台数据中心服务器的各种设备上运行。
『机器学习进阶笔记』系列将深入解析TensorFlow系统的技术实践,从零开始,由浅入深,与大家一起走上机器学习的进阶之路。
前面几篇文章讲述了在Computer Vision领域里面常用的模型,接下来一段时间,我会花精力来学习一些TensorFlow在Computer Vision领域的应用,主要是分析相关pape和源码,今天会来详细了解下fast neural style的相关工作,前面也有文章分析neural style的内容,那篇算是neural style的起源,但是无法应用到实际工作上,为啥呢?它每次都需要指定好content image和style image,然后最小化content loss 和style loss去生成图像,时间花销很大,而且无法保存某种风格的model,所以每次生成图像都是训练一个model的过程。
而fast neural style中能够将训练好的某种style的image的模型保存下来,然后对content image 进行transform,当然文中还提到了image transform的另一个应用方向:Super-Resolution,利用深度学习的技术将低分辨率的图像转换为高分辨率图像,现在在很多大型的互联网公司,尤其是视频网站上也有应用。
Paper原理
几个月前,就看了Neural Style相关的文章 深入理解Neural Style,Neural Algorithm of Aritistic Style 中构造了一个多层的卷积网络,通过最小化定义的content loss和style loss最后生成一个结合了content和style的图像,很有意思,而Perceptual Losses for Real-Time Style Transfer and Super-Resolution,通过使用perceptual loss来替代per-pixels loss使用pre-trained的vgg model来简化原先的loss计算,增加一个transform Network,直接生成Content image的style版本, 如何实现的呢,请看下图,容我道来:
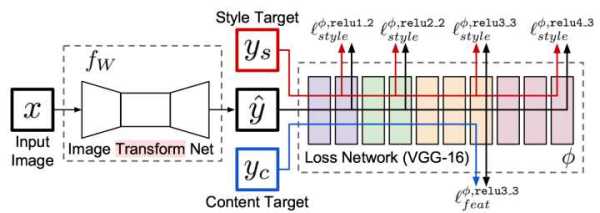
整个网络是由部分组成:image transformation network、 loss netwrok;Image Transformation network是一个deep residual conv netwrok,用来将输入图像(content image)直接transform为带有style的图像;而loss network参数是fixed的,这里的loss network和 A Neural Algorithm of Artistic Style 中的网络结构一致,只是参数不做更新(PS:这里我之前可能理解有点小问题 —— neural style的weight也是常数,不同的是像素级loss和per loss的区别,neural style里面是更新像素,得到最后的合成后的照片),只用来做content loss 和style loss的计算,这个就是所谓的perceptual loss,作者是这样解释的,为Image Classification的pretrained的卷积模型已经很好的学习了perceptual和semantic information(场景和语义信息),所以,后面的整个loss network仅仅是为了计算content loss和style loss,而不像 A Neural Algorithm of Artistic Style 做更新这部分网络的参数,这里更新的是前面的transform network的参数,所以从整个网络结构上来看输入图像通过transform network得到转换的图像,然后计算对应的loss,整个网络通过最小化这个loss去update前面的transform network,是不是很简单?
loss的计算也和之前的都很类似,content loss:
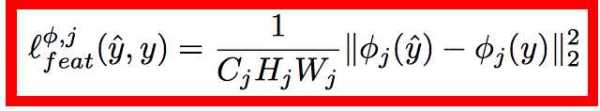
style loss:

style loss中的gram matrix:
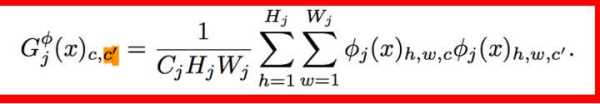
Gram Matrix是一个很重要的东西,他可以保证y^hat和y之间有同样的shape。 Gram的说明具体见paper这部分,我这也解释不清楚,相信读者一看就明白:

相信看到这里就基本上明白了这篇paper在fast neural style是如何做的,总结一下:
- transform network 网络结构为deep residual network,将输入image转换为带有特种风格的图像,网络参数可更新。
- loss network 网络结构同之前paper类似,这里主要是计算content loss和style loss, 注意不像neural style里面会对图像做像素级更新更新。
- Gram matrix的提出,让transform之后的图像与最后经过loss network之后的图像不同shape时计算loss也很方便。
Fast Neural Style on Tensorflow
代码参考[OlavHN/fast-neural-style](https://github.com/OlavHN/fast-neural-style),但是我跑了下,代码是跑不通的,原因大概是tensorflow在更新之后,local_variables之后的一些问题,具体原因可以看这个issue:<tf.train.string_input_producer breaks when num_epochs is set · Issue #1045 · tensorflow/tensorflow>.还有这个项目的代码都写在一起,有点杂乱,我将train和最后生成style后的图像的代码分开了,项目放到了我的个人的github neural_style_tensorflow,项目基本要求:
- python 2.7.x
- Tensorflow r0.10
- VGG-19 model
- COCO dataset

时间:2018-08-02 00:13 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
最新文章

热门文章















