Lucene 倒排索引缓冲池的细节
文章来源: https://github.com/zzboy/lucene/blob/master/lucene%E5%80%92%E6%8E%92%E7%B4%A2%E5%BC%95%E7%BC%93%E5%86%B2%E6%B1%A0%E7%9A%84%E7%BB%86%E8%8A%82.md
倒排索引要存哪些信息
提到倒排索引,第一感觉是词到文档列表的映射,实际上,倒排索引需要存储的信息不止词和文档列表。为了使用余弦相似度计算搜索词和文档的相似度,需要计算文档中每个词的TF-IDF值,这样就需要记录词在每个文档中出现的频率以及包含这个词的文档数量,前者需要对应每个文档记录一个值,后者就是倒排表长度。除此以外,为了能够高亮搜索结果,需要记录每个词在文档中的偏移信息(起始位置和长度),为了支持短语查询,需要记录每个词的 position 信息,注意 position 和 offset 不是一个概念,position 是文档分词之后得到的 term 序列中词的位置,offset 是分词之前的偏移,如果文档中一个词被分成多个 Term,那么这些 Term 将共享同一个 position,典型场景是同义词,这在自然语言处理中很有用。如果用户希望在 Term 级别干预查询打分结果,那么就需要对文档中的每个词存储额外的信息(payload)。
综上,倒排索引需要存储的信息主要有以下几方面:
- 词(Term)
- 倒排文档列表(DocIDList)
- 词频(TermFreq)
- Position
- Offset
- Payload
有几点需要特别说明,lucene 中 Term 是对每个 Field 而言的,也就是说在 Document 不同 Field 中出现的相同字面的词也算不同的 Term。搞清楚了这一点,就很容易理解 TermFreq、Position、Offset、Payload 都是在一个 Document 中 Field 下的统计量。另外,同一个 Term 在同一个 Document 的同一个 Field 中,Position、Offset、Payload 可能会出现多次,次数由 TermFreq 决定。
lucene 中倒排索引的逻辑结构如下:
|+ field1(name,type)
|+ term1
|+ doc1
|+ termFreq = 2
|+ [position1,offset1,payload1]
|+ [position2,offset2,payload2]
|+ doc2
|+ termFreq = 1
|+ [position3,offset3,payload3]
|+...
|+ term2
|+...
|+ field2(name,type)
|+ ...
lucene 建索引的过程
上面倒排索引的逻辑结构贯穿 lucene 的始终,lucene 建索引的不同阶段对应逻辑结构的某种具体实现。
分词阶段所有倒排信息被缓存在内存中,随着缓存的数据越来越多,刷新逻辑会被触发(FlushPolicy),内存中缓存的数据会被写入外存,这部分被写入外存的数据称为段(Segment),段是倒排索引逻辑结构的另外一种表示方式,lucene 使用有限状态转移自动机(FST)来表示,这一块后面会有文章深入讨论,本篇文章主要讨论内存中缓存对倒排索引逻辑结构的实现方式。再多说几句为什么 lucene 会使用段这一概念。首先,lucene 建索引是线程安全的,线程安全的实现方式很高效,一般的实现线程安全的方式是对临界变量加锁,lucene 没有采用这种方式。用一个比喻来形容 lucene 的方式,假如对临界变量加锁的方式是多个人在一个工作间里工作,共享这个工作间里的工具,lucene 就是给每个人一个工作间,大家工作时互不干扰。这样每个人的工作成果就可以同时输出,效率自然就高了很多,这里的工作成果便是段。其次,机器的内存资源是有限的,不可能把所有数据都缓存在内存中。最后,从查询的角度看,将查询条件分发给多个段同时查询最后再 merge 各个段的查询结果的方式比单一段查询效率要高。当然,事物总是矛盾的,有利必有弊,使用段的方式给索引管理带来了很大的难度,首当其冲便是索引的删除,用户下发删除 Query,这些 Query 要应用到所有已经存在的段上,如果同时应用删除操作,磁盘 IO 必将受不了,lucene 选择的删除时机是在段合并的时候,在这之前,删除 Query 会被缓存起来,这又带来另一个问题,如果每个段要维护自己的删除 Query 内存必然受不了,怎么让所有段共享删除 Query。使用段带来的另一个复杂度便是段的合并。在多少个段上同时查询效率最高是一个需要权衡的问题,段太多太少都会导致查询很慢,因此段合并策略很重要。上面提到的这些都会在接下来的文章中深入讨论。
回到本篇文章的主题,内存缓存是怎么实现上面的倒排索引的逻辑结构的。
缓存实现倒排索引逻辑结构的方式
首先来看下 Term、DocIdList、TermFreq、Position、Offset、Payload 产生的时间点。Term 刚开始分词的时候就有,根据上面的讨论,这个时候 Position、Offset、Payload 也都产生了,也就是说分词结束,Term、Position、Offset、Payload 就都可以写到缓存里面,TermFreq 这个时候还没有得到最终的值,主要有两点原因,第一,这里讨论的缓存都是针对 Field 而言的,如果一个 Document 里面包含多个相同的 Field,这些相同的 Field 显然要被写到同一个缓存里面,同一个 Term 在这些 Field 里可能会出现多次,每次出现 TermFreq 就要加 1。第二,一个 Field 中 Term 也可能会出现多次。基于以上两点,只有当遇到下一个 Document 的时候前一个 Document 的各个 TermFreq 的值才能够固定,这个时候就可以将 TermFreq 和 DocId 一起写到缓存。
lucene 里面实现缓存的最基础的组件是org.apache.lucene.util.ByteBlockPool,lucene 的缓存块都是基于这个类构建的,这个类的官方解释如下:
The idea is to allocate slices of increasing lengths For example, the first slice is 5 bytes, the next slice is 14, etc. We start by writing our bytes into the first 5 bytes. When we hit the end of the slice, we allocate the next slice and then write the address of the new slice into the last 4 bytes of the previous slice (the "forwarding address").
Each slice is filled with 0's initially, and we mark the end with a non-zero byte. This way the methods that are writing into the slice don't need to record its length and instead allocate a new slice once they hit a non-zero byte.
具体实现请直接参考源码,实现很简单,类的功能是可以将字节数据写入,但是不要求写入的逻辑上是一个整体的数据在物理上也是连续的,将逻辑上的数据块读出来只需要提供两个指针就好了,一个是逻辑块的物理起始位置,一个是逻辑块的物理结束位置,注意逻辑块的长度可能是小于两个结束位置之差的。ByteBlockPool 要解决的问题可以联系实际的场景来体会下,不同 Term 的倒排信息是缓存在一个 ByteBlockPool 中的,不同 Term 的倒排信息在时序上是交叉写入的,Term 到达的顺序可能是term1,term2,term1,并且每个 Term 倒排信息的多少是无法事先知道的。
ByteBlockPool 解决的另一类问题是时序上顺序的数据,比如 Term,虽然整体上看 Term 到达的顺序可能是term1,term2,term1这样交叉的情况,但是 Term 数据有的一个特点是只会被写到缓存块中一次。
上面提到的 ByteBlockPool 解决的两类问题对应两类缓存块,[DocIDList,TermFreq,Position,Offset,Payload] 缓存块和 Term 缓存块,前一个缓存块存放的是除了 Term 字面量外余下的数据。完整的倒排信息不止这两个缓存块,怎么将两个缓存块联接起来构建成倒排索引,还需要有其他的数据。
下面是别人画的一张图,lucene3.0 的实现,很老了,但是整体上思路没有变。
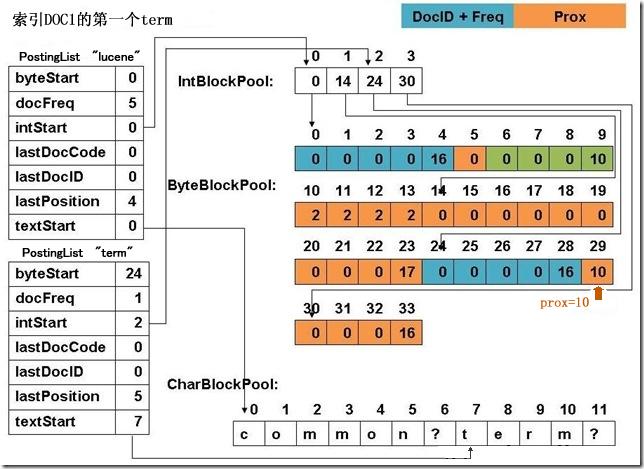
左侧是 PostingList,每个 Term 都有一个入口,其中 byteStart 字段存放的是之前提到的这个 Term 对应的倒排信息 [DocIDList,TermFreq,Position,Offset,Payload] 在缓存块中的物理偏移,textStart 用于记录该 Term 在 Term 缓存块中的偏移,lucene5.2.1 中,Term 缓存块没有用 CharBlockPool,而是用 ByteBlockPool。上文提到 DocID、TermFreq 的写入时机和 Position、Offset、Payload 是不一样的,因此 lucene 在实际实现中并没有将 [DocIDList,TermFreq,Position,Offset,Payload] 当成一个数据块,而是分成了两个数据块 [DocIDList,TermFreq] 和[Position,Offset,Payload],这样为了获得这两块数据就需要记录四个偏移地址,但 lucene 并没有这样做。byteStart 记录 [DocIDList,TermFreq] 的起始偏移地址,[Position,Offset,Payload]的偏移地址可以通过 byteStart 计算出来,要理解这一点需要理解 ByteBlockPool 是怎么实现逻辑上连续的数据物理上离散存储的,这一块不打算展开,感兴趣的读者请直接看 ByteBloackPool 的源码,类似于链表的结构,链表的 Node 对应这里叫做 Slice,Slice 的末尾会存放 Next Slice 的地址。其实之前提到的两个物理偏移就对应头 Slice 的起始位置和尾 Slice 的结束位置。数据块 [DocIDList,TermFreq] 和[Position,Offset,Payload]的头 Slice 是相邻的,所有头 Slice 的大小都是相同的,因此 [Position,Offset,Payload] 的开始位置很容易从 byteStart 推算出。这样只需要记录三个偏移地址就够了,byteStart、[DocIDList,TermFreq]块的结束位置、[Position,Offset,Payload]块的结束位置。后两个信息 lucene 将其为维护在一个 IntBlockPool 中,IntBlockPool 和 ByteBlockPool 的区别仅仅是存储的数据类型不同,PostingList 中记录下这两个偏移在 IntBlockPool 中的偏移。
上图中左侧除了上面讨论的外,可以看到还有 lastDocID、lastPosition 等,这些都是为了做差值编码,节约存储。这里还有个问题需要说明下,新到达的 Term,怎么判断其是新的还是已经存在了。针对这个问题 lucene 对 Term 做了一层 Hash,对应的类是org.apache.lucene.util.BytesRefHash, 功能解释如下:
BytesRefHash is a special purpose hash-map like data-structure optimized for BytesRef instances. BytesRefHash maintains mappings of byte arrays to ids. storing the hashed bytes efficiently in continuous storage. The mapping to the id is encapsulated inside BytesRefHash and is guaranteed to be increased for each added BytesRef.
综上所述,lucene 对缓存的实现可谓煞费苦心,之所以做的这么复杂我觉得有以下几点考虑:
- 节约内存。比如用那个三个指针记录两个缓存块的偏移、Slice 长度的分配策略、差值编码等。
- 方便对内存资源进行控制。几乎所有数据都是通过 BlockPool 来管理的,这样的好处是内存使用情况非常容易统计,FlushPolicy 很容易获取当前的内存使用情况,从而触发刷新逻辑。
- 缓存不必针对每个 Field,也就是说同一个 Segment 所有 Field 的数据可以放在一块缓存中,每个 Field 有自己的 PostingList,所有 Field 的 Term 字面量共享一个缓存以及上层的 Hash,这样便能很大程度上节约存储空间。对应一个具体的 Field,判断 Term 是否存在首先判断在 Term 缓存块中是否存在,接着判断 PostingList 中是否有入口。
下一篇将介绍上面的逻辑倒排结果在段中是怎么表示的,也就是缓存怎么刷到外存上的。

时间:2018-11-11 23:33 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
















