腾讯QQ大数据:聚类算法如何应用在营收业务中—
导语 同一催费场景,挖掘人群特点,不同人群触达不同文案与图片提升转化
背景
“尊敬的XXX用户,您的话费已不足10元。为了您的正常使用,请及时充值。”
——移动公司
“温馨提示:XXX先生/小姐,您的住房贷款将于11月5日扣款,请在此账号中存足款项。”
——家银行
就算是在尊敬的称谓,就算是再温馨的话语,还是感觉有些冷冰事故,千里追债。
通信和金融业务,算是每个现代人的“刚性”需求。收到催费通知尚且不爽,何况是偏向娱乐的互联网业务催费通知。如何能让人觉得不突兀,稍微有点打动人心的感觉?以3年前某业务合作案例为例,抛砖引玉,与各位一起讨论从数据角度发现数据规律,同样是让用户付费场景,通过挖掘出不同用户的付费G点,以不同群体推送不同文案与图片的方式实现个性化催费,推动业务增长。
数据探索过程中12个字感悟:大胆想象,敢于尝试,小心验证
7步骤完成整个流程

行动
Step 1:大胆想象
和“传统”垄断行业相比,我们有哪些优势?
有数字化的用户数据。以计算机和网络为框架的服务模式,天然将用户属性和行为数字化并记录下来,变成和营收一样,公司最大的资产。
哪种服务是温度的,能打动人心的?
唯有高端私人定制。不管是葛大爷、白百何电影中的“圆梦方案”,还是大众辉腾使馆区的线下定制中心,均体现出浓浓的顶级个性化的感觉,红尘万千,只为伊人。这不正是互联网服务的终极吗?个性服务,千人千面。然而圆梦方案终究灯亮散场,低调辉腾亦低调隐退。
为什么?粒度太细,难以形成规模效益,导致每一单的成本太高,整体盈利太少。催费如果要做到真正千人千面,投入太高,收益暂时难以评估。所以初期尝试,我们化“点”为“面”,粒度不是每个人,而是某类人。
Step 2:数据发现挖掘点
算法+数据 => 增长点
如何化“点”为“面”,识别人群,在事先没有预期目标的情况下,称手的工具就是聚类算法了。
• 1 算法
聚类算法简单来讲,就是把全部对象按照其特征的距离远近,划分成若干簇。这些簇满足以下条件:
1)一个簇内部对象距离近
2)不同簇对象的距离远

类似于上图显示的效果,中心点为集群的核心,围绕中心点近的一批就是同一个簇。很容易分出来不同类别,不同业务特性的群体。分群体运营,比较容易获得更好的效果。
举个例子,比如某个业务的特征包括以下几类,具体应该如何应用聚类算法呢?
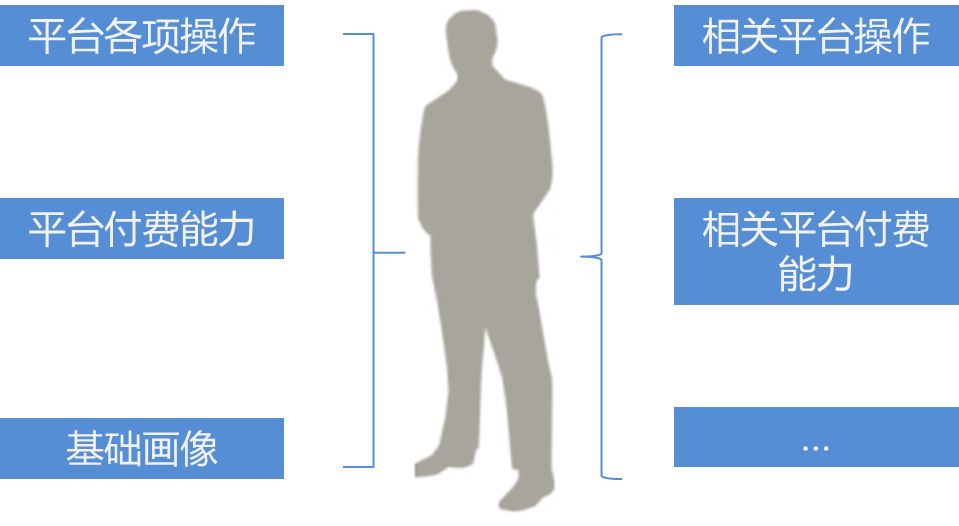
• 2 特征标准化
收集完上述行为数据后,需要对数据做“标准化”处理。标准化方式方法很多,这里做一个简单举例。
为什么要做标准化处理?这涉及到聚类算法K-means的实现原理。K-means是一种基于距离的迭代式算法,它将n个观察实例分类到k个聚类中,以使得每个观察实例距离它所在的聚类的中心点比其他的聚类中心点的距离更小。其中,距离的计算方式可以是欧式距离(2-norm distance),或者是曼哈顿距离(Manhattan distance,1-norm distance)或者其他。以我们初中学的欧式距离为例
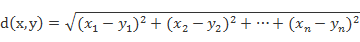
其中为两个对象的对应特征量,比如都是播放时长,单位为秒。同理
为周播放天数。秒的量纲远远大于周播放天数,一首2分钟的歌曲有120秒的播放时长,一周无休播放,也只有7天的播放天数。最终导致播放天数对距离计算影响小,聚类特性偏向播放时长。其他常用的计算距离方法同样存在类似问题,比如:
曼哈顿距离:
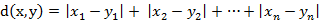
闽科夫斯基距离:

解决思路在于无量纲化,方法就是标准化。
我们这次采用的是Z-score标准化,公式如下:
其中x为某一具体分数,μ为平均数,σ为标准差。
标准分数可以回答这样一个问题:”一个给定分数距离平均数多少个标准差?”在平均数之上的分数会得到一个正的标准分数,在平均数之下的分数会得到一个负的标准分数。
• 3 聚类结果输出与解释
得到三个有业务意义的簇,在三维空间上的投影如下:(由于业务敏感性,忽略具体描述)
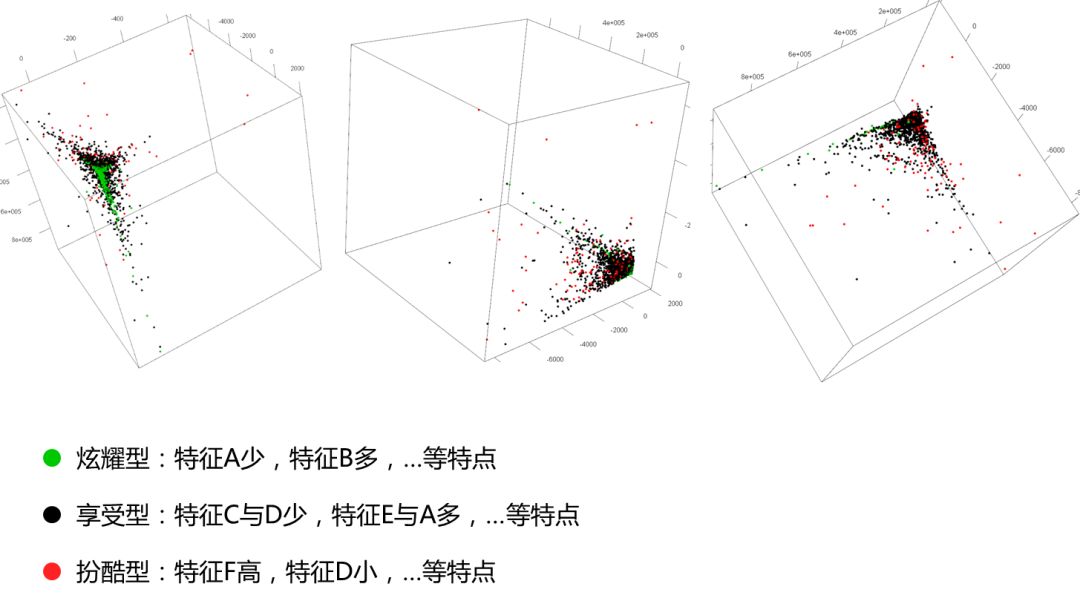
可以看到,每种类别在空间中的位置和集中程度都有区别,我们就根据这些差异总结出上面三种类型的不同特点。接下来依据不同特点做不同的催费方式。
Step 3:产品沟通
与产品沟通,推动方案落地。由于业务关系,这里不做累述
说服产品经验技巧:
• 深知运营痛点,瓶颈点
• 成功案例举证(首个案例,靠个人或团队影响力)
• 算法初探举例
Step 4:线上测试
我们需要一种快速的,低成本的验证方法。在整体流程不变,后台接口不变的约束下,有什么替换图片与文档的方法更快速,风险和成本更低呢?通过多次迭代优化,所以最终效果如下:通过改变紫色框中的图片与红色框中的文案,对不同用户群体进行不同图片与文案触达

Step 5:效果跟踪与评估
7天流量灰度测试的结果如下:
• 1 常规的线上实际转化效果对比
衡量指标:成功发送催费消息到支付成功转化率均值
炫耀型:x1% 享受型:x2% 扮酷型:x3% 参照组:c1%
x2 > x1 > x3 > c1
• 2 因素影响显著性论证
好了,看到实验组的均值高于参照组,说明有效果。扩大灰度、发邮件、收工了?那么问题来了,如何知道上述效果是个性化文案导致的,还是环绕周围的随机性造成的?
将这个问题转换为统计学的问题,实验组和参照组的均值差异是显著的?
我们可以使用方差分析来尝试解答。方差分析(Analysis of Variance,简称ANOVA),又称“变异数分析 ”,是R.A.Fisher发明的,用于两个及两个以上样本 均数差别的显著性检验 。
工具我们使用喜闻乐见的R,套路如下:

由此我们可以大致认为,不同组的均值差异受不可控随机因素影响的可能性小,差异来自可控因素,基于用户行为的个性化文本的影响。
Step 6:自动化运营
用户数据+模型例行化,各接口联调,部署上线
Step 7:效果监控
通过邮件,短信,QQ,微信等各种形式对效果进行长期监控,关注变化情况及时优化。
[1]. Z-score
http://baike.baidu.com/link?url=n2HbtKxAC_wAyGEJMN-D7wwZNg2B3-dFa-0W9W8sAFJWf5BTry5hIAG6RlFWl-zlWNUUJht85XhoLIy4Hg9Gj_
[2]. 归一化
http://baike.baidu.com/link?url=egN4K40qIsxRxknS6uvOlL63MFGx5LCUq12ojBI-3caMRCYAM5WihO_o2t6vHP0rQKfyei-LKVuN7kbg4HExRK
[3]. K-means
http://www.cnblogs.com/bourneli/p/3645049.html
[4]. 方差分析
http://baike.baidu.com/link?url=-OkUo0mu0bfo9-F9PjvVXR5rdk02I16lJT3UHXDy0I66je4e0t2s-8dpAHW6FxYWf8m36hP-Bs69CJMH-MUJ-lyrRtqbKB9nFQZ0qregXmNvqO0deQNEOT4w_RJ9EaNw

时间:2018-09-25 00:24 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]缓存与数据库双写一致性
- [数据挖掘]揭开AWS的Timestream数据库的面纱
- [数据挖掘]设计bug导致数据被删除,java工程师背锅被开除:
- [数据挖掘]Oracle 行贿 10 万元:中标 1980 万元数据库项目
- [数据挖掘]"存算分离"已成为分布式数据库的主流方
- [数据挖掘]万众期待的华为鸿蒙来了,成为全球第三大操作
- [数据挖掘]从传感器到人工智能——常用八大传感器盘点
- [数据挖掘]属于 Hadoop 的大数据时代已结束
- [数据挖掘]流数据并行处理性能比较:Kafka vs Pulsar vs Praveg
- [数据挖掘]Angular、React 和 Vue 三大框架,Web 开发该如何选择
相关推荐:
网友评论:
















